Building a Local-First Agent Framework in Rust (Part 3): Modeling Messages, Roles, and Sessions

See Part 0 for the latest table of contents and sample code. New chapters will be added over time.
Chapter 3: Modeling Messages, Roles, and Sessions
The previous chapter gave abcb a place to live. This chapter gives it the first thing an agent framework actually needs: a conversation.
That may sound obvious. A model receives messages and returns messages. But the shape of those messages matters. Once the framework starts calling tools, recording events, replaying sessions, and recovering from failures, a conversation is no longer just a list of strings. Each message has a role. Each session has an identity. The framework needs to serialize the data, test it, clone it, compare it, and pass it between layers without wondering who owns the text.
Why do messages need roles?
This is partly because many model APIs, including OpenAI-style chat APIs, represent a conversation as role-tagged messages. But the reason is more general than one API. A role tells the framework how to interpret a message. A user's request, a model's answer, a system instruction, and a tool result may all be text, but they do not mean the same thing. If the framework stores them as plain strings, it has to recover that meaning from position or convention. If the role is part of the data, the meaning travels with the message.
This is why the conversation shape belongs near the center of the framework, not only inside the code that happens to call a model API. The model caller may change later. The meaning of a user message, an assistant message, a system instruction, or a tool result should not.
In this series, a provider is the part of the framework that knows how to ask a model for the next response. Later it will be an abstraction that can be backed by a scripted mock or a real local HTTP model server. Either way, the provider should receive a clear conversation shape instead of a loose pile of strings.
So before we define a provider, before we call a model, and before we build the loop, we define the domain model. By domain model, I mean the Rust types that represent the concepts this framework cares about: messages, roles, and sessions. They are not UI details, file paths, or command-line options. They are the vocabulary the rest of the framework will use when it talks about a conversation.
The sample code for this chapter is in chapter03/abcb/.
3.1 The Core Crate Appears
This is the chapter where abcb-core enters the workspace.
File: abcb/Cargo.toml
[workspace]
members = ["crates/abcb-cli", "crates/abcb-core"]
resolver = "3"
# ...
[workspace.dependencies]
serde = { version = "1.0.228", features = ["derive"] }
serde_json = "1.0.149"
The split is small, but meaningful. The CLI still owns command-line parsing and local configuration. The core crate owns the concepts that are not specific to the CLI. Messages, roles, and sessions are not command-line details. They are the foundation of the framework, so they belong in a library crate that other crates can depend on later.
The previous chapter parsed TOML config. This chapter saves the domain model as JSON and reads it back again. That matters because agent frameworks are often JSON-shaped at the boundaries: model APIs, tool arguments, event logs, eval fixtures, and saved sessions all end up needing serialization.
The code in abcb-core is short enough to read in one sitting. Most of the chapter works from abcb/crates/abcb-core/src/lib.rs.
3.2 Roles
The first type is Role.
File: abcb/crates/abcb-core/src/lib.rs
#[derive(Clone, Debug, Deserialize, Eq, PartialEq, Serialize)]
#[serde(rename_all = "snake_case")]
pub enum Role {
User,
Assistant,
System,
Tool,
}
An enum is the right shape for this because the set is closed. A message in this framework is not allowed to have any arbitrary role. It is one of four known roles, and nothing else.
User is the person asking for something. Assistant is the model's reply. System is the instruction layer that tells the model how to behave. Tool is the environment talking back to the model.
That last one is important even though it does not do much yet. In a normal chat transcript, there may be only user and assistant messages. In an agent loop, the outside environment has to speak too. By environment, I mean the things the model can ask the framework to do: read a file, run a command, inspect a project, or report that an action was denied. If the model asks to call a tool, the result has to come back into the conversation somehow. Later, when a tool returns a file listing, a calculation result, an error message, or a denial from the approval policy, that information will be appended as a Tool message so the model can decide what to do next.
The #[serde(rename_all = "snake_case")] attribute controls the JSON shape. Role::Assistant becomes "assistant", not "Assistant". That matches the style used by many model APIs and keeps the serialized form stable.
The derives are doing real work:
File: abcb/crates/abcb-core/src/lib.rs
#[derive(Clone, Debug, Deserialize, Eq, PartialEq, Serialize)]
Serialize and Deserialize are serde derive macros. They generate the code that turns Role into JSON and restores it from JSON. Debug gives the type a readable {:?} representation, so format!("{:?}", Role::Assistant) produces "Assistant" for tests and logs. PartialEq and Eq let tests compare values directly with == and !=. Clone allows deliberate duplication with .clone() when a later function needs its own copy. We will come back to the difference between Copy and Clone later. These are not decoration. They are capabilities we are choosing to give the type.
The first test locks down the serialized form:
File: abcb/crates/abcb-core/src/lib.rs
#[test]
fn role_round_trips_as_snake_case_json() {
let json = serde_json::to_string(&Role::Assistant).expect("role should serialize");
assert_eq!(json, r#""assistant""#);
let role: Role = serde_json::from_str(&json).expect("role should deserialize");
assert_eq!(role, Role::Assistant);
}
This is a small test, but it catches a common kind of drift. If someone removes the serde rename attribute later, the Rust type may still compile, but the JSON contract will change. The test makes that visible.
3.3 Messages Own Their Text
3.3.1 A Short Rust Memory Model
Before looking at Message, it is worth pausing on the Rust idea behind its memory model. Rust values have owners. At any moment, each value has exactly one owner, and when that owner goes out of scope, the value is dropped. A String owns text stored in a heap allocation, so dropping the String also frees that heap memory. Rust checks this at compile time, without a garbage collector and without asking us to call free().
{
let s = String::from("hi");
// `s` owns the String here.
}
// `s` is out of scope, so the String has been dropped.
Ownership can also move from one variable to another.
let s1 = String::from("hi");
let s2 = s1;
// println!("{s1}"); // This would not compile.
After let s2 = s1, s2 owns the string. s1 no longer does. This is why Rust often says that a value has been "moved."
Borrowing is the other side of the model. A borrow lets code access a value without taking ownership of it. The borrowed value is a reference. A shared reference, written &T, allows read-only access and many shared references can exist at the same time. An exclusive reference, written &mut T, allows mutation, but only one can be active at a time.
The practical rule is short: many readers or one writer, but not both at the same time. People sometimes call this "shared XOR mutable."
let mut values = vec![1, 2, 3];
let first_read = &values;
let second_read = &values;
println!("{first_read:?} {second_read:?}");
let writer = &mut values;
writer.push(4);
The & operator creates a reference. The * operator dereferences a reference, which means it accesses the value being borrowed. In day-to-day Rust, you do not write * as often as you might expect because method calls and formatting usually auto-dereference for you. But the idea matters: &x means "borrow x," and *r means "use what r points to."
This notation is easy to confuse because the same symbols appear in different places. In let r: &String = &s, the &String on the left says the type of r is "reference to String." The &s on the right creates that reference from the value s. In let writer: &mut Vec<i32> = &mut values, both sides are mutable-reference versions of the same idea. (Here, i32 is Rust's primitive signed 32-bit integer type. We will touch Rust's primitive types later.)
The * operator goes the other direction. If r is a reference, *r means "the value behind the reference." If you have a reference to a reference, such as &&str, then **r follows both layers. Most of the time Rust hides this through auto-deref, but reading the symbols is still useful: & adds a reference layer, and * removes one.
The next type is Message.
File: abcb/crates/abcb-core/src/lib.rs
#[derive(Clone, Debug, Deserialize, Eq, PartialEq, Serialize)]
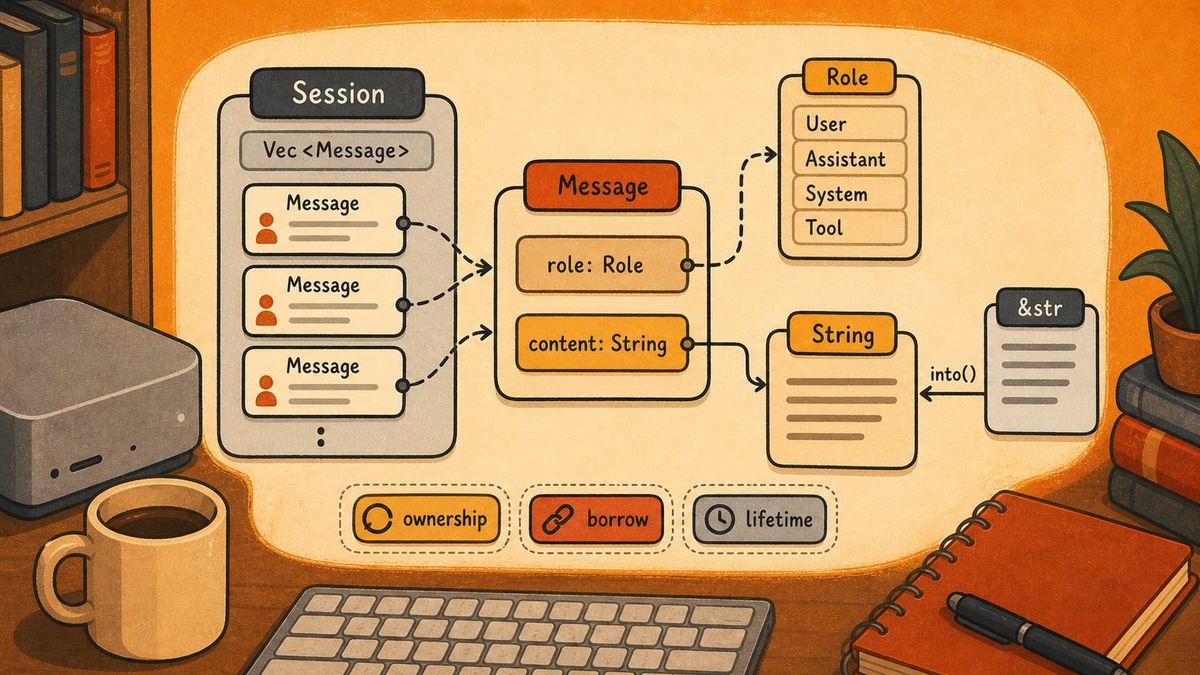
pub struct Message {
pub role: Role,
pub content: String,
}
A message is a role plus content. The interesting choice is that content is a String, not a borrowed &str.
This is the first real ownership decision in the project.
3.3.2 String and &str
In Rust, String and &str are related, but they are not the same thing. A String is owned, heap-allocated, and growable. A &str is a borrowed view into UTF-8 text owned somewhere else. That owner might be a String, a string literal baked into the program, or some other buffer.
let owned: String = String::from("hello");
let borrowed: &str = &owned;
let literal: &str = "hello";
There is also a bare str type. It represents UTF-8 text, but the type itself has no fixed compile-time size. Even when the compiler sees a literal like "hello", the value we use in code is a &'static str: a reference to string data stored in the program. The reference has a known size, pointer plus length, while the underlying str may be any byte length.
We will revisit 'static later when we talk about lifetimes. For now, the important point is size. Local variables and ordinary struct fields need a known size. A &str is sized because it is a pointer (to the text buffer) plus a length. A String is also sized because the value itself is a pointer, length, and capacity, even though the text buffer it owns lives elsewhere on the heap. If Message tried to store bare str, it would not be the normal sized value we need to put in a Vec<Message>.
We will look at Vec more closely in the next section. For now, you can think of Vec<Message> as a growable list whose elements all have the same known type and size. That rules out bare str as a direct message field. The practical pair is String for owned text and &str for borrowed text.
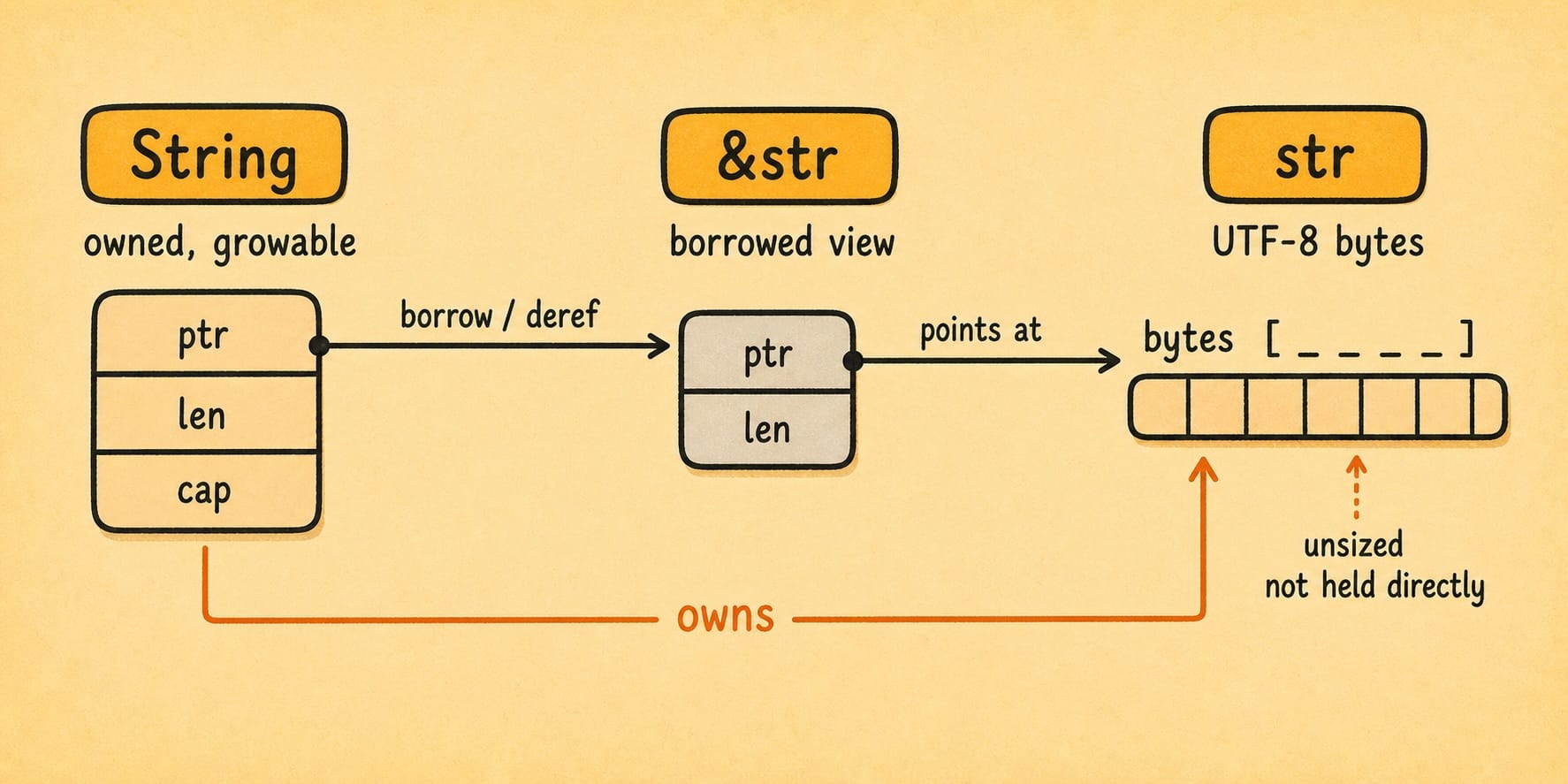
A common API pattern follows from that: functions often accept &str when they only need to read text, while structs store String when they need to own text.
fn print_label(label: &str) {
println!("{label}");
}
pub struct Label {
pub text: String,
}
The Message type is a struct that stores text. It is not just borrowing text for a moment. It represents part of a conversation that may outlive the function that created it. That is why content is a String.
Why&str, not&String?
A&Stringis a reference to one specific owned string type. A&stris a reference to string contents. That makes&strmore flexible: it can point into aString, a string literal, or another string buffer. When a function only needs to read text,&strusually says the intent better than&String.
A String can live inside the message for as long as the message exists. A &str is a borrowed view into text owned somewhere else. Borrowed views are useful, but they come with lifetimes. If Message borrowed its content, then every Message would have to say how long that borrowed content is valid. Then Session would have to carry that lifetime too. Then functions that store sessions, pass them to providers, serialize them, or append tool results would also become lifetime-aware.
That can be correct in some programs. It is the wrong default here.
Messages are domain values. They move through the framework. They may be stored in a session, serialized to disk, cloned in a test, passed to a model provider, or kept after an error so the run can be summarized. They should not depend on a temporary string owned by whichever function happened to create them. Owning the content is simpler and more honest.
This is one of the recurring patterns in the series: when the framework needs to keep data, store owned values. Borrow only when the borrowed value is clearly temporary.
The constructor keeps call sites ergonomic:
File: abcb/crates/abcb-core/src/lib.rs
impl Message {
pub fn new(role: Role, content: impl Into<String>) -> Self {
Self {
role,
content: content.into(),
}
}
}
The parameter is impl Into<String>, which means callers can pass a String or a string literal. Inside the constructor, content.into() turns it into an owned String.
3.3.3 Constructors and Conversions
Rust does not have a special built-in constructor feature. Instead, types usually define associated functions. An associated function belongs to the type, not to an existing value, so you call it with Type::function_name(...). This is similar to a static method in some other languages.
The name new is a convention. It usually means "make the normal starting value for this type."
let mut values: Vec<i32> = Vec::new();
let mut text: String = String::new();
Vec::new() makes an empty vector. String::new() makes an empty string. These are useful when you plan to build the value over time by pushing, inserting, or appending. Sometimes Rust needs a type annotation, like Vec<i32>, because an empty vector does not yet contain a value that tells the compiler what element type it should use.
Message::new(...) follows the same convention, but it is not empty. A message needs a role and content, so the associated function takes those values and returns a complete Message.
The Into<String> part is about conversion. Into is a trait, which is Rust's way to describe behavior a type can support. You can think of a trait as similar to an interface: it says, "types that implement this can do this operation."
From and Into are a pair. If a type knows how to build itself from another type, Rust can usually use that relationship in the other direction too.
let owned = String::from("hello");
let also_owned: String = "hello".into();
String::from("hello") reads as "make a String from this string literal." "hello".into() reads as "convert this value into the type the surrounding code expects." In the constructor, impl Into<String> lets the caller provide either kind of string-like input while Message still stores a real owned String.
That gives us the convenience of borrowed input without making the domain type borrowed.
There is also a small Rust idiom here. The constructor ends with Self { ... } and no semicolon. We saw the same style in the previous chapter with Ok(()). In Rust, the last expression in a block is the return value. We could write return Self { ... };, but the shorter form is the usual style. The expression is not just building a struct. It is the function's returned value.
The message test is direct:
File: abcb/crates/abcb-core/src/lib.rs
#[test]
fn message_round_trips_through_json() {
let message = Message::new(Role::User, "hello");
let json = serde_json::to_string(&message).expect("message should serialize");
let restored: Message = serde_json::from_str(&json).expect("message should deserialize");
assert_eq!(restored, message);
}
Again, expect() is fine here. The test is not recovering from malformed input. It is asserting that a value we constructed should serialize and deserialize. If it does not, the test should fail clearly.
3.4 Sessions Collect Messages
The final type in this chapter is Session.
File: abcb/crates/abcb-core/src/lib.rs
#[derive(Clone, Debug, Deserialize, Eq, PartialEq, Serialize)]
pub struct Session {
pub id: String,
pub messages: Vec<Message>,
}
A session has an ID and a vector of messages. This is the conversation history the framework will send to the model.
Vec<Message> is the right starting point because the session grows over time. A user message goes in. The model replies. Later, the model may ask for a tool. The tool result goes in. The model sees the updated conversation and decides what to do next. The order matters, and the number of messages is not fixed. That is exactly what a vector is for.
3.4.1 Vec<T> and Arrays
Rust has both arrays and vectors. They are different types with different jobs.
An array has a fixed length that is part of its type. In [i32; 3], the element type is i32 and the length is 3.
let a: [i32; 3] = [10, 20, 30];
Conceptually, the whole value is the three integers. For Copy values like i32, copying the array copies the values themselves.
let b = a; // copies all 12 bytes; a and b are independent
println!("{:?}", b); // [10, 20, 30] — unchanged
A Vec<T> is different. It is growable, so the actual elements live in a heap allocation. The Vec value itself is a small owner of that allocation: pointer, length, and capacity.
let v: Vec<i32> = vec![10, 20, 30];
That ownership matters. If Rust allowed a Vec to be copied by simply duplicating its pointer, length, and capacity, two vectors would think they owned the same heap buffer. Dropping both would try to free the same allocation twice. That is exactly the kind of bug Rust's ownership model prevents.
let v = vec![10, 20, 30];
let w = v; // ownership moves to w; v is no longer usable
// println!("{:?}", v); // this would not compile
Rust moves the Vec instead of copying it, so there is still only one owner of the heap buffer.
So the session's messages: Vec<Message> field says two things at once: the message list can grow as the conversation continues, and the session owns the messages it contains.
Like Message, Session owns its data. It owns the ID string and the vector. The vector owns its messages. The messages own their content. This means a session and all of its message content can survive outside the function that created it. That will matter later when a run fails but we still want the session and event log to describe what happened.
The constructor starts with an empty message list:
File: abcb/crates/abcb-core/src/lib.rs
impl Session {
pub fn new(id: impl Into<String>) -> Self {
Self {
id: id.into(),
messages: Vec::new(),
}
}
pub fn push_message(&mut self, message: Message) {
self.messages.push(message);
}
}
push_message is a method. In Rust, methods are functions defined inside an impl block, and they usually take self, &self, or &mut self as their first parameter. That first parameter represents the value the method is called on. Because push_message changes the session, it takes &mut self. That lets us call session.push_message(...) while Rust treats it as a mutable borrow of session for the duration of the method call.
self,&self, and&mut self&selfmeans the method borrows the value immutably. It can read the value but cannot change it.&mut selfmeans the method borrows the value mutably. It can change the value, then the borrow ends and the caller can keep using the same value.selfmeans the method takes ownership of the value. That is useful when the method consumes the value, transforms it into another value, or follows a builder style and returnsSelfagain. Ownership does not come back automatically; if the caller should keep using the value, the method has to return it.
The method takes message: Message by value because the session becomes the owner of that message. After the caller pushes a message into the session, the caller no longer owns it. That is the move.
This is a useful place to feel Rust's ownership model in ordinary code. Passing a Message into push_message transfers ownership into the vector. Passing &mut self borrows the session mutably for the duration of the method call, then gives it back. Nothing dramatic is happening, but the design is precise: the session owns the conversation, and callers may mutate the session only when they have mutable access to it.
The session test proves the whole structure round-trips:
File: abcb/crates/abcb-core/src/lib.rs
#[test]
fn session_round_trips_through_json() {
let mut session = Session::new("session-1");
session.push_message(Message::new(Role::System, "You are abcb."));
session.push_message(Message::new(Role::User, "Create a scene."));
let json = serde_json::to_string(&session).expect("session should serialize");
let restored: Session = serde_json::from_str(&json).expect("session should deserialize");
assert_eq!(restored, session);
}
This test is small, but it is the first proof that the domain model (in this case Session, Message, and Role) can leave memory and come back intact. That ability will become important almost immediately. Event logs, session files, tool arguments, and model outputs all depend on the same discipline: data that crosses a boundary needs a stable shape.
3.5 Why Not Borrow?
The central decision in this chapter is that the domain types own their fields.
It is worth being explicit because Rust makes the alternative available. We could define a message like this:
pub struct BorrowedMessage<'a> {
pub role: Role,
pub content: &'a str,
}
That type says: this message does not own its content. It only points at text owned somewhere else, and the message cannot outlive that text. The 'a lifetime is the compiler's way of tracking that relationship.
3.5.1 Lifetimes
A lifetime is the span of code during which a borrow is valid. It is not a runtime value, and it is not garbage collection. It is part of Rust's compile-time analysis. No lifetime metadata is attached to a reference at runtime.
Most of the time, Rust can infer lifetimes for local code. If a borrow is created and used inside one function, the compiler can see where it starts and where it stops. But once references cross a boundary, for example by being stored in a struct, passed into a function, or returned from a function, Rust sometimes needs the relationships to be named.
That is what 'a does in BorrowedMessage<'a>. It says that the content reference is valid for some lifetime named 'a, and the borrowed message cannot outlive that borrowed text. We are not creating a lifetime by writing 'a; we are naming the relationship so the compiler can check it.
A classic example is a function that returns one of two borrowed strings. Written without lifetimes, the relationship is ambiguous:
// Returns the longer of two string slices.
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}
This does not compile. The returned &str borrows from something, but the compiler cannot tell whether it is tied to x or y. With an explicit lifetime, we name the relationship:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}
In English, this says: x, y, and the returned reference are all valid for some lifetime 'a. The caller does not write 'a at the call site. The compiler infers it from the actual references and checks that the returned reference is not used after either input has become invalid.
Where does'ago?
The most common place to see a lifetime is on a reference type, such as&'a str. Read that as "a reference tostrthat is valid for lifetime'a." When we introduce a lifetime name ourselves, we usually declare it in an angle-bracketed generic parameter list first, as infn longest<'a>(...)orstruct BorrowedMessage<'a>. The lifetime name can then be used inside that function or type definition.'staticis a special lifetime name that means "valid for the entire program." A string literal like"hello"has type&'static str, because the text is stored in the program itself.
Borrowed data is not bad. It is often exactly right. Later, when the HTTP provider builds a request, we will borrow data so the request can be serialized without allocating new strings. But borrowed domain models tend to spread lifetimes through the rest of the system. A borrowed Message<'a> leads to a borrowed Session<'a>, which leads to providers and loops that also need to care about 'a. That is more complexity than this domain model needs.
For this framework, messages and sessions are long-lived values. They are the things being passed around, stored, and inspected. Owning their data is the conservative choice, and here that conservatism keeps the rest of the framework easier to reason about.
The cost is allocation and occasional cloning. That cost is acceptable here. A local agent loop is not bottlenecked on the cost of storing a few strings in a conversation. It is bottlenecked on model calls, tool execution, and human iteration. The simpler ownership model is worth more than a theoretical allocation saving.
3.6 What We Have So Far
At the end of this chapter, abcb has its first shared library crate and its first domain model.
It knows that a conversation is a session. A session has messages. A message has a role and content. Roles are a closed set. Messages and sessions own their data. Rust gives us the pieces to say that directly: enums for closed choices, structs for grouped data, String and Vec for owned values, and derives plus serde for JSON serialization. The domain model can leave memory and come back without losing its shape.
This still does not call a model. That comes next.
But the model call will now have something concrete to receive. The next chapter defines the first major abstraction in the framework: a provider, something that can look at a session and produce the next assistant message.



