Go Reference Type: Slices vs. Maps


Recently, I reviewed some coding interview questions. There was a problem with which solution used DFS over a graph with recursive calls. My solution was in Go and has a recursive function:
func dfsVisit(curr int, graph map[int][]int,
currPath *[]int, visited map[int]struct{}) {
...
}Source 1) A function signature for the recursive DFS visit
currrepresents the current visiting node id.graphrepresents the adjacency list of graph nodes.currPathis to record the current visiting path in a stack for backtracking algorithm. It should be maintained across recursive calls.-
visitedis a cache for the previously visited nodes. It also should be maintained across recursive calls.
The code was customary, yet an intriguing aspect caught my attention: why is currPath defined as a "pointer" to a slice, whereas visited is simply a map?
Go has no reference types
There is a famous Go commit log: "spec: Go has no 'reference types'." However, Go FAQ still has an entry saying that maps, slices, and channels are references.
Why are maps, slices, and channels references while arrays are values?
What occurred? The key idea here is that Go doesn't have 'reference types,' but utilizes 'references' - or "act as references."
Ok, now we know that maps, slices, and channels work as references. Let's check it with maps first.
import "fmt"
func updateVisited(node int, visited map[int]struct{}) {
visited[node] = struct{}{}
}
func printVisited(node int, visited map[int]struct{}) {
if _, ok := visited[node]; ok {
fmt.Printf(">> visited node %d\n", node)
} else {
fmt.Printf(">> not visited node %d\n", node)
}
}
func main() {
var (
visited = make(map[int]struct{})
node = 1
)
printVisited(node, visited)
updateVisited(node, visited)
printVisited(node, visited)
}
Source 2) Updating a map within a function
>> not visited node 1
>> visited node 1
The calling function can update the map
We can see that updating a map within a function call retains changes. However, this is not true for slices.
import "fmt"
func updateSlice(node int, currPath []int) {
currPath = append(currPath, node)
}
func main() {
var (
currPath = []int{1, 2}
newNode = 3
)
fmt.Printf(">> currPath: %v\n", currPath)
updateSlice(newNode, currPath)
fmt.Printf(">> currPath: %v\n", currPath)
}
Source 3) Updating a slice within a function
>> currPath: [1 2]
>> currPath: [1 2]
The calling function cannot append an item to the slice
If we want to update a slice within another function call, we should give the pointer of a slice.
import "fmt"
func updateSlice(node int, currPath *[]int) {
*currPath = append(*currPath, node)
}
func main() {
var (
currPath = []int{1, 2}
newNode = 3
)
fmt.Printf(">> currPath: %v\n", currPath)
updateSlice(newNode, &currPath)
fmt.Printf(">> currPath: %v\n", currPath)
}
Source 4) Updating a slice within a function via the pointer argument
>> currPath: [1 2]
>> currPath: [1 2 3]
The calling function can append an item to the slice via a pointer argument
So, it seems that the FAQ document is wrong: slices look just like values. Unfortunately, no, it's not that simple. Slices actually also have some reference-like behaviors. Let's update the slice as the following code.
import "fmt"
func updateSlice(node int, currPath []int) {
n := len(currPath)
currPath[n-1] = node
}
func main() {
var (
currPath = []int{1, 2}
newNode = 3
)
fmt.Printf(">> currPath: %v\n", currPath)
updateSlice(newNode, currPath)
fmt.Printf(">> currPath: %v\n", currPath)
}
Source 5) Updating a slice within a function without modifying the size of the slice
>> currPath: [1 2]
>> currPath: [1 3]
Now, changes made during a function call are preserved, which can be perplexing. To comprehend this, we must go deep into the internals of Go slices.
Go Slice Internals
TL;DR:
- Go slice variable refers to a
slicestruct instance. - Go slice uses a reference to its "backing array."
Go defines slice with the runtime.slice struct type.
// src/runtime/slice.go
type slice struct {
array unsafe.Pointer
len int
cap int
}
Source 6) The Go slice definition
The array is the reference to the backing array. The line represents the length of the slice, and the cap defines the capacity of the slice. Please check "Not understanding slice length and capacity" for more details about slice length and capacity.
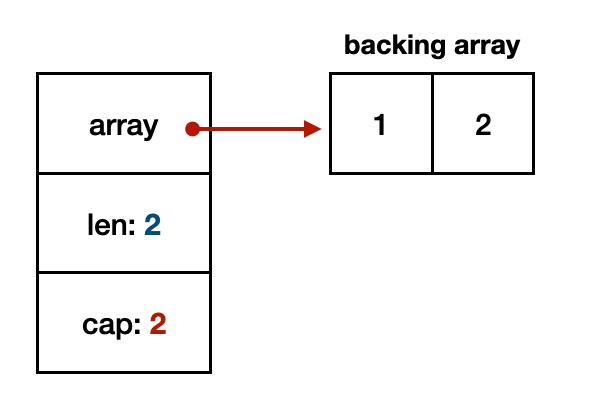
When we create the currPath slice instance with []int{1, 2}, it creates a length-2 and capacity-2 slice instance with the initial values of 1 and 2.
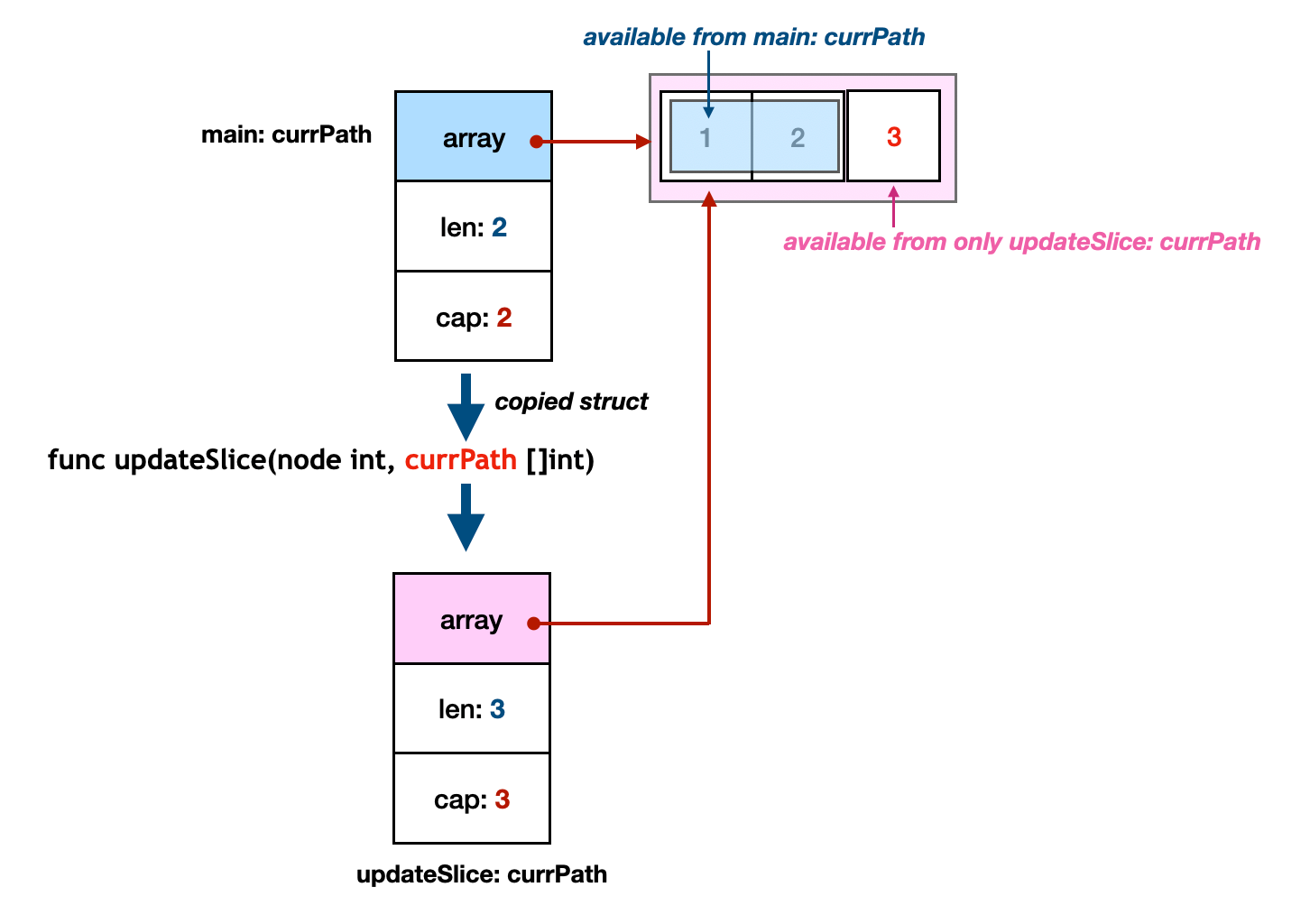
If we give a slice as a function argument, it will be passed as a value. So, the function argument has a copied slice struct. If we append an element to the slice struct, the length and the capacity will be updated. However, the update is only valid inside of the function. Outside the function, the passed slice struct's length and capacity are still 2.
However, the copied slice struct has a pointer to the backing array. The [] with slices works as the reference. Therefore, we can modify the backing array inside of the function.
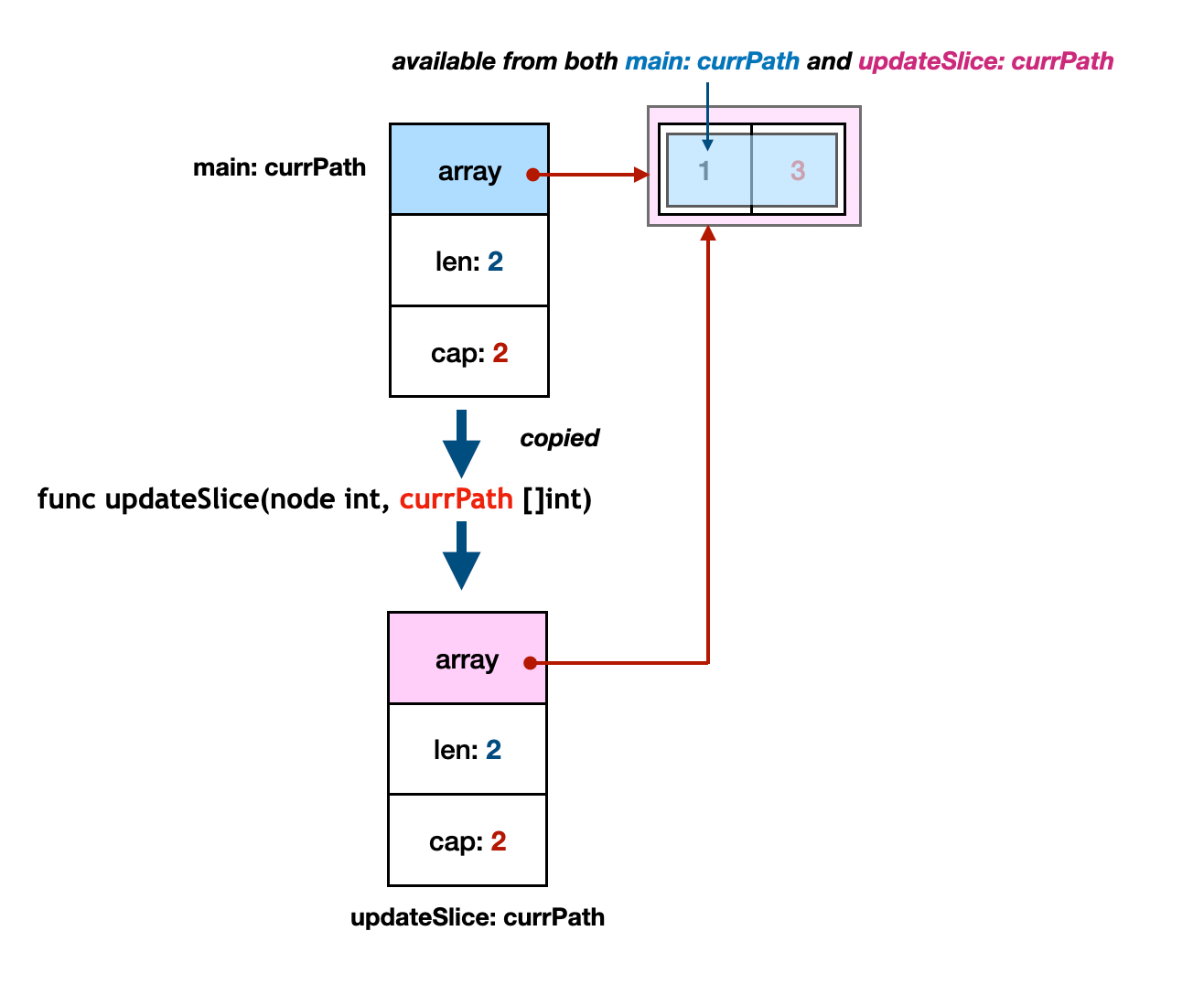
Go doesn't consider[]as an operator by definition. I just use[]because I don't know what would be the proper term for it in Go.
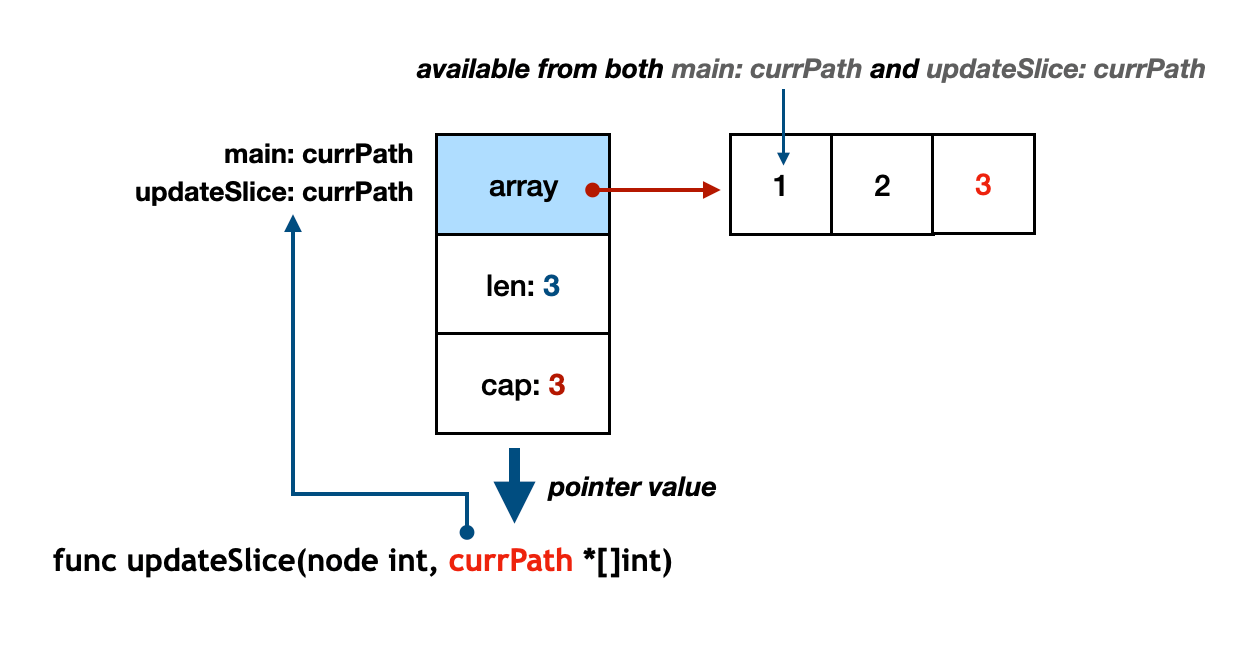
So, we can modify the slice within a function if we only modify the backing array - without updating its capacity and length. But, I believe that it would be too error-prone, and we'd better pass a pointer of the slice if we need to update and maintain the slice.
Go Map Internals
Then, why do maps work differently? That's because the Go map type is a pointer to the runtime.hmap struct.
// src/runtime/map.go
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
Source 7) The Go map definition
Please check the great article "Map and memory leaks" for more details on Go Maps.
The map is a pointer value by itself. So, we can just hand over the map variable into a function argument. We don't need to use the * operator with the function argument. That's a bit confusing, but practically, we have only one way to access maps: the []. And the [] works as a reference, so we wouldn't have a chance to see * operators for maps.
You can see that the makemap function (the function called when the compiler creates (with make) a map) returns a pointer of hmap struct.
// src/runtime/map.go
// makemap implements Go map creation for make(map[k]v, hint).
// If the compiler has determined that the map or the first bucket
// can be created on the stack, h and/or bucket may be non-nil.
// If h != nil, the map can be created directly in h.
// If h.buckets != nil, bucket pointed to can be used as the first bucket.
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
if overflow || mem > maxAlloc {
hint = 0
}
...
}
Source 8) The Go implementation of the map creation
You might wonder if you seemakeslicefunction that it returns aunsafe.Pointervalue instead ofslice. I believe the compiler casts theunsafe.Pointerintoslicein somewhere. You can also see that thegrowslice(the function called when Go extends the backing array) returnsslicestruct.
This is why we opt for pointers of slices and values of maps as mutable function arguments. This approach might be somewhat confusing, but I (also) believe - as the FAQ item suggests - it significantly enhances the usability of the language.
There's a lot of history on that topic. Early on, maps and channels were syntactically pointers, and it was impossible to declare or use a non-pointer instance. Also, we struggled with how arrays should work. Eventually, we decided that the strict separation of pointers and values made the language harder to use. Changing these types to act as references to the associated, shared data structures resolved these issues. This change added some regrettable complexity to the language but had a large effect on usability: Go became a more productive, comfortable language when it was introduced.



