Building a Local-First Agent Framework in Rust (Part 7): The Model's Envelope and One Step

See Part 0 for the latest table of contents and sample code. New chapters will be added over time.
Chapter 7: The Model's Envelope and One Step
Chapter 6 gave abcb a set of capabilities. A tool can have a name, a description, and an implementation. The framework can register several tools in one registry and look them up by name..
But the model still has no way to ask for one.
This post is also available on Medium. If you’re a paid Medium member and happen to read it there, it helps fund my next cup of coffee. Much appreciated ☕️😄
That is the next boundary. If a model only returns ordinary text, the framework has to guess what the text means. Is this a final answer? Is it asking to call echo? Is it trying to call a tool that does not exist? Is the argument object valid? Human readers may understand the intention, but a framework needs something stricter than intention. It needs a contract.
This chapter adds that contract as ModelOutput. It is a small JSON envelope around the model's response. For now, the model can say one of two things:
{"kind":"final","content":"all done"}
or:
{"kind":"tool_call","tool_name":"echo","arguments":{"text":"hello"}}
What is an envelope?
I am using the word envelope in the ordinary sense first. An envelope wraps something and gives the receiver enough information to handle it. A paper envelope may carry an address outside and a letter inside. In this chapter, the JSON envelope wraps the model's actual decision and gives the framework akindfield so it knows how to handle the response.
That may look like a small change, but it is one of the core ideas of an agent framework. The model does not simply produce text anymore. It produces a structured decision that the framework can parse, check, and act on.
We are still not building the full loop yet. Chapter 8 will do that. This chapter builds one step: ask the provider for one response, parse it as a model envelope, and either return a final answer or execute one tool.
The sample code for this chapter is in chapter07/abcb/.
7.1 The Envelope Is the Model's Side of the Contract
In Chapter 5, we named three JSON-shaped layers:
- Message: conversation data sent to and from the provider
- Envelope: the model's structured decision
- Event: the audit trail of what happened in the framework
This chapter makes the envelope layer real. I called it the middle layer because it sits between the conversation message and the framework event: the model returns text inside a message, the framework parses that text as an envelope, and then the framework may record what happened as an event.
A message is still just conversation data:
File: abcb/crates/abcb-core/src/lib.rs
#[derive(Clone, Debug, Deserialize, Eq, PartialEq, Serialize)]
pub struct Message {
pub role: Role,
pub content: String,
}
The role field tells us who a message belongs to. In the current code, there are four roles. A user message is what the human asks. A system message is an instruction from the framework or application. An assistant message is the model's reply. A tool message is a tool result that can later be sent back to the model.
When we call a provider, we give it the session so far. This is worth saying plainly: the model does not remember our Rust Session by itself. Each provider call needs the framework to send the relevant context again. The provider then returns the model's next reply. In our abstraction, that reply is normalized as an assistant Message, even if the underlying API or local model server uses a different raw response shape.
Keeping that return value as Message lets a hosted model API such as OpenAI, Anthropic, or Gemini, a local model server, and our mock provider fit the same interface.
The new rule is about the content of the assistant message returned by the provider. Until now, the content could be any text. In this chapter, the framework starts asking the model to return JSON in a specific shape. That shape describes the model's decision: either produce a final answer or request a tool call. We will represent that JSON as a Rust enum named ModelOutput, and later in the chapter we will add run_step, the function that asks the provider for one response and interprets that response as a ModelOutput.
Can every model return this kind of JSON?
No. Returning structured output is a model capability, and it is one of the practical tests for whether a model fits this kind of agent framework. Some models can follow a strict JSON instruction reliably, especially when the schema is small and examples are included in the prompt. Some models can do it only sometimes: they may add prose before the JSON, omit required fields, rename keys, or return almost-correct JSON with a small syntax error. Smaller local models can be especially uneven here, depending on the model, quantization, prompt, and decoding settings.
I do not think we should decide this only from a model card or a benchmark. A simple framework-level test is better: give the model ten or twenty requests, require only the envelope shape we define here, and count how many outputs parse asModelOutputwithout repair. Then test the harder cases: ask for a final answer, ask for a tool call, ask for a tool call with nested arguments, and ask for something ambiguous. If the model cannot consistently produce parseable envelopes, the framework either needs a repair layer, a more constrained decoding method, native structured-output support from the provider, or a different model.
This distinction matters. Message is the transport shape. ModelOutput is the decision shape. The model may speak through an assistant message, but the framework does not act on the raw text directly. It first parses the text into an envelope.
That gives us a cleaner failure point. If the model returns invalid JSON, that is a model-output parse error. If the model names a missing tool, that is an unknown-tool error. If the tool receives bad arguments, that is a tool error. Those are different failures, and the framework should not blur them together.
7.2 ModelOutput
The envelope is an enum:
File: abcb/crates/abcb-core/src/lib.rs
#[derive(Clone, Debug, Deserialize, PartialEq, Serialize)]
#[serde(tag = "kind", rename_all = "snake_case")]
pub enum ModelOutput {
ToolCall {
tool_name: String,
arguments: serde_json::Value,
#[serde(default)]
note: Option<String>,
},
Final {
content: String,
},
}
This uses the same internally tagged enum pattern we used for Event. The kind field tells serde which variant to build. rename_all = "snake_case" means ToolCall becomes "tool_call" in JSON and Final becomes "final".
The two variants describe two decisions:
Final: the model is done and the framework can return the content.ToolCall: the model wants the framework to run a named tool with JSON arguments.
The ToolCall variant also has an optional note. A model may use this to include a short explanation of why it is calling the tool. We do not use the note yet, but it is a useful place for non-executable context.
The important serde detail is:
#[serde(default)]
note: Option<String>,
#[serde(default)] tells serde what to do when the field is missing during deserialization: use that field's default value instead of failing. For Option<String>, the default value is None. Serde already treats a missing Option field this way, so in this exact case the attribute is not strictly required. I still like keeping it here because it makes the protocol decision visible: the note field is optional, and missing it should not make the envelope invalid.
That means both of these are valid:
{"kind":"tool_call","tool_name":"echo","arguments":{"text":"hi"},"note":"checking echo"}
and:
{"kind":"tool_call","tool_name":"echo","arguments":{"text":"hi"}}
In the resulting Rust value, the first JSON object becomes a ModelOutput::ToolCall with note: Some("checking echo".into()). The second becomes a ModelOutput::ToolCall with note: None.
One other detail is easy to miss. ModelOutput derives PartialEq, but not Eq:
#[derive(Clone, Debug, Deserialize, PartialEq, Serialize)]
This is enough for the tests in this chapter. PartialEq lets us compare two ModelOutput values with == or assert_eq!. In the current serde_json crate, Value also implements Eq, so this enum could derive Eq too. We are not using that stronger promise yet, so the derive stays at the level the code needs.
PartialEqandEqPartialEqis the trait behind==and!=. If a type implementsPartialEq, Rust values of that type can be compared for equality.Eqis a stronger marker trait. It does not add new methods, but it says equality behaves like normal mathematical equality, including the rule that a value is equal to itself.
The classic counterexample is floating-pointNaN: in Rust,f64implementsPartialEq, but notEq, becauseNaN == NaNis false. That means a struct containing anf64usually cannot deriveEq. A struct containing onlyString,i32, or other fully comparable values usually can.
So the practical rule is simple: derivePartialEqwhen you need ordinary comparisons in tests or logic. AddEqwhen every field supports it and you want to promise full equality behavior.
That connects back to the derive discussion from Chapter 3. Derives are not just decorations. They are promises about what the type can support.
7.2.1 serde_json::Value
The tool call arguments use serde_json::Value:
arguments: serde_json::Value,
Value is serde JSON's general-purpose representation of JSON data. It can hold null, booleans, numbers, strings, arrays, and objects. It is not untyped in the sense of "anything at all." It is typed as JSON data. But it is open enough that the envelope does not need to know the exact argument schema for every tool.
That is a deliberate boundary.
The envelope needs to carry the model's requested arguments. The registry needs to find the tool by name. The concrete tool needs to validate the argument shape it expects.
For example, Echo expects a JSON object with a string field named text:
File: abcb/crates/abcb-tools/src/echo.rs
#[derive(Deserialize)]
struct EchoArgs {
text: String,
}
fn invoke(&self, args: &serde_json::Value) -> Result<String, ToolError> {
let typed: EchoArgs = serde_json::from_value(args.clone())?;
Ok(typed.text)
}
AddNumbers expects a different shape:
File: abcb/crates/abcb-tools/src/add_numbers.rs
#[derive(Deserialize)]
struct AddArgs {
a: f64,
b: f64,
}
fn invoke(&self, args: &serde_json::Value) -> Result<String, ToolError> {
let typed: AddArgs = serde_json::from_value(args.clone())?;
let sum = typed.a + typed.b;
Ok(format!("{sum}"))
}
The envelope should not need an enum variant for every tool's argument struct. That would make the core framework depend on every possible tool. Instead, ModelOutput carries the JSON arguments as a Value, and each tool parses the value into its own typed argument struct.
This is one of the places where the framework stays generic while the tools stay specific.
7.3 Parsing the Envelope
Parsing is intentionally small:
File: abcb/crates/abcb-core/src/lib.rs
#[derive(Debug)]
pub enum ModelOutputError {
Parse(serde_json::Error),
}
impl ModelOutput {
pub fn parse(raw: &str) -> Result<ModelOutput, ModelOutputError> {
Ok(serde_json::from_str(raw)?)
}
}
ModelOutput::parse accepts raw text and returns a typed envelope. If the text is invalid JSON, parsing fails. If the JSON is valid but does not match the expected shape, parsing also fails. For example, an unknown kind value cannot become a ModelOutput variant.
Those failures are wrapped in ModelOutputError:
pub enum ModelOutputError {
Parse(serde_json::Error),
}
For now, there is only one variant because all envelope parsing failures come from serde JSON. The separate error type is still useful because it names the layer that failed. A serde_json::Error can happen while reading an event log, parsing tool arguments, or parsing model output. ModelOutputError says this one happened while trying to understand the model's envelope.
The tests make these cases concrete:
File: abcb/crates/abcb-core/src/lib.rs
#[test]
fn parse_final_envelope() {
let raw = r#"{"kind":"final","content":"all done"}"#;
let output = ModelOutput::parse(raw).expect("should parse");
assert_eq!(
output,
ModelOutput::Final {
content: "all done".into()
}
);
}
#[test]
fn parse_rejects_unknown_kind() {
let raw = r#"{"kind":"banana","content":"x"}"#;
let err = ModelOutput::parse(raw).expect_err("should fail");
assert!(matches!(err, ModelOutputError::Parse(_)));
}
This is still a simple parser, but the design point is important. The model's response is not trusted as executable intent until it passes through this parser.
That does not make the system safe by itself. A parsed envelope can still ask for the wrong tool or pass poor arguments. But it gives the framework a typed place to start checking.
7.4 Envelopes Are Not Events
It is tempting to think of ModelOutput as an event because it records something the model said. But it is not an event.
An envelope is the model-facing contract. It answers the question: "What decision did the model return?"
An event is the audit-facing record. It answers the question: "What happened in the framework?"
Those questions are related, but not identical. For example, the model might return this envelope:
{"kind":"tool_call","tool_name":"echo","arguments":{"text":"hello"}}
That is what the model said. After parsing it, the framework may look up the tool, invoke it, receive "hello" as the output, and later record several events around that process. The envelope is one input to the framework's behavior. The event log is the record of the behavior.
How does the model know which tool to call?
The model does not know our Rust registry by itself. The framework has to tell the model which tools exist, usually by putting tool names, descriptions, and argument shapes into the prompt or by passing tool schemas through a provider's native tool-calling API.
Many modern LLMs have been trained to follow tool-calling patterns. That helps, because the model may already understand the idea of choosing a tool and filling in arguments. But the specific tools still come from the framework.echo,add_numbers, andsession_note_searchare not universal model knowledge. They become available only becauseabcbregisters them and describes them to the model.
This is another reason the envelope matters. The model's tool-calling ability is useful only if the framework can turn the model's choice into a checked runtime action.
In this chapter, run_step does not write events yet. That is intentional. We are isolating one responsibility: can the framework interpret one model decision and act on it? Once that works, the loop can decide how to record the step.
This is the same layering habit from the event-log chapter. If every type has a clear job, the agent loop can grow without every piece becoming the same vague "history."
7.5 Step Outcome
run_step needs to report what happened during one step. For that, the code adds StepOutcome:
File: abcb/crates/abcb-core/src/lib.rs
#[derive(Clone, Debug, PartialEq)]
pub enum StepOutcome {
Final(String),
ToolExecuted { tool_name: String, output: String },
}
This is not the final event log format, and it is not the conversation history. It is the return value of one step.
If the model returns a final envelope, the outcome is:
StepOutcome::Final(content)
If the model returns a tool call and the tool runs successfully, the outcome is:
StepOutcome::ToolExecuted { tool_name, output }
The distinction matters because Chapter 8 will need to look at the outcome and decide what happens next. A final answer can stop the loop. A tool result usually needs to be fed back into the conversation so the model can continue.
For now, run_step reports the outcome and stops. That keeps this chapter focused on one decision at a time.
7.6 Loop Errors
run_step sits above the provider, the parser, and the tools. So its error type needs to compose errors from several layers:
File: abcb/crates/abcb-core/src/lib.rs
#[derive(Debug)]
pub enum LoopError {
Provider(ProviderError),
Parse(ModelOutputError),
UnknownTool(String),
Tool(ToolError),
}
The name LoopError may look slightly early because we are not writing the full loop yet. But the step already belongs to the loop layer. It coordinates provider output, envelope parsing, registry lookup, and tool invocation.
The variants are intentionally separate:
Provider: the provider failed before the framework got a model response.Parse: the provider returned text that did not parse asModelOutput.UnknownTool: the model named a tool that is not registered.Tool: the requested tool failed.
These are not just different messages for the same failure. They are different recovery opportunities.
If the provider is exhausted, a mock test may simply fail. If the model output does not parse, a future loop may ask the model to repair its JSON. If the tool name is unknown, the loop may remind the model of available tools. If the tool arguments are invalid, the loop may report the schema mistake. We cannot make those choices well if all errors are flattened too early.
The conversion impls make ? work across layers:
File: abcb/crates/abcb-core/src/lib.rs
impl From<ProviderError> for LoopError {
fn from(e: ProviderError) -> Self {
LoopError::Provider(e)
}
}
impl From<ModelOutputError> for LoopError {
fn from(e: ModelOutputError) -> Self {
LoopError::Parse(e)
}
}
impl From<ToolError> for LoopError {
fn from(e: ToolError) -> Self {
LoopError::Tool(e)
}
}
With these impls, a function returning Result<_, LoopError> can use ? on a Result<_, ProviderError>, Result<_, ModelOutputError>, or Result<_, ToolError>. Rust knows how to convert each lower-level error into the loop-layer error.
UnknownTool is different. It is not converted from another error type. The registry lookup returns Option<&dyn Tool>, not Result. That was a design choice in Chapter 6. The registry only says whether a name exists. The loop layer decides that a missing tool name is a LoopError::UnknownTool.
7.7 One Step
Here is the whole step:
File: abcb/crates/abcb-core/src/lib.rs
pub fn run_step(
provider: &mut impl Provider,
registry: &ToolRegistry,
user_message: impl Into<String>,
) -> Result<StepOutcome, LoopError> {
let mut session = Session::new("run-step");
session.push_message(Message::new(Role::User, user_message));
let reply = provider.complete(&session)?;
let output = ModelOutput::parse(&reply.content)?;
match output {
ModelOutput::Final { content } => Ok(StepOutcome::Final(content)),
ModelOutput::ToolCall {
tool_name,
arguments,
..
} => {
let tool = registry
.get(&tool_name)
.ok_or_else(|| LoopError::UnknownTool(tool_name.clone()))?;
let output = tool.invoke(&arguments)?;
Ok(StepOutcome::ToolExecuted { tool_name, output })
}
}
}
The shape is:
- Create a session.
- Add the user message.
- Ask the provider for one assistant message.
- Parse the assistant message content as
ModelOutput. - Match on the envelope.
- Return a final answer or execute one tool.
The match is the important control point:
match output {
ModelOutput::Final { content } => ...
ModelOutput::ToolCall { tool_name, arguments, .. } => ...
}
Because ModelOutput is an enum, Rust checks that the match handles every variant. If we later add another variant, such as Think or AskApproval, the compiler will point at this match and make us decide how run_step should handle it.
For example, imagine we changed the enum like this:
pub enum ModelOutput {
ToolCall { /* fields omitted */ },
Final { content: String },
Think { content: String },
}
The existing match would no longer be complete. Rust would report that the ModelOutput::Think pattern is not covered. That is what I mean by the compiler helping us find the places where the protocol is interpreted. The new protocol variant cannot quietly exist in the type while run_step ignores it by accident. We have to add an arm, return an error, or consciously choose a catch-all pattern.
7.7.1 The .. Pattern
The tool-call arm uses a pattern we have not focused on yet:
ModelOutput::ToolCall {
tool_name,
arguments,
..
} => {
...
}
The .. means "ignore the remaining fields." In this case, the remaining field is note.
We could write:
ModelOutput::ToolCall {
tool_name,
arguments,
note: _,
} => {
...
}
But .. is shorter and more flexible. It says this arm only needs tool_name and arguments. If the variant later gets another field that this code does not need, the pattern does not have to change immediately.
This is useful, but it should be used with care. Sometimes explicitly naming ignored fields is clearer, especially if ignoring the field is a meaningful decision. Here, note is optional explanatory text and run_step does not use it yet, so .. is a reasonable fit.
7.8 The Tool Call Path
The tool-call branch has two important operations:
File: abcb/crates/abcb-core/src/lib.rs
let tool = registry
.get(&tool_name)
.ok_or_else(|| LoopError::UnknownTool(tool_name.clone()))?;
let output = tool.invoke(&arguments)?;
First, the framework asks the registry for a tool with the requested name. The registry returns Option<&dyn Tool>. If the tool does not exist, ok_or_else turns the None into a LoopError::UnknownTool.
ok_or_else is the lazy version of ok_or. It takes a closure and only creates the error if the option is None. Here, that means we clone tool_name only when we actually need the error:
ok_or_else(|| LoopError::UnknownTool(tool_name.clone()))
If the tool exists, ? unwraps the Some value and gives us &dyn Tool.
Second, the framework invokes the tool:
let output = tool.invoke(&arguments)?;
The tool receives the raw JSON arguments from the envelope. It validates them internally, using its own argument type. If validation fails, the tool returns ToolError::InvalidArguments, and ? converts that into LoopError::Tool.
This branch is the first time the model's structured output crosses into framework action. The model names a tool and supplies arguments. The framework checks the registry, calls the tool, and returns a typed outcome.
It is still only one step. The tool result does not yet go back into the model context. That comes next. But the hinge is now in place.
7.9 The Run Command
The CLI adds a run command for this one-step flow:
File: abcb/crates/abcb-cli/src/main.rs
#[derive(Debug, Subcommand)]
enum Command {
/// Check the local abcb development environment.
Doctor,
/// Send a single user message and print the assistant reply.
Chat {
/// The user message to send.
message: String,
/// Use the in-process mock provider (required while no real provider exists).
#[arg(long)]
mock: bool,
/// Append JSONL event records to this file. When omitted, no events are recorded.
#[arg(long, value_name = "PATH")]
log: Option<PathBuf>,
},
/// Read a JSONL event log and print the recorded event sequence.
Replay {
/// Path to a JSONL event log file produced by `abcb chat --log`.
path: PathBuf,
},
/// Run one agent step against the tool registry and print the outcome.
Run {
/// The user message to send.
message: String,
/// Use the in-process mock provider (required while no real provider exists).
#[arg(long)]
mock: bool,
},
}
The implementation still uses MockProvider, because there is no real provider integration yet:
File: abcb/crates/abcb-cli/src/main.rs
fn run_run(message: String, mock: bool) -> Result<(), Box<dyn Error>> {
if !mock {
return Err(
"only --mock is supported right now; pass --mock to use the mock provider".into(),
);
}
let mut provider = MockProvider::new([format!(
r#"{{"kind":"final","content":"mock run: you said {message}"}}"#
)]);
let registry = default_registry(PathBuf::from(NOTES_PATH));
match run_step(&mut provider, ®istry, &message)? {
StepOutcome::Final(content) => println!("{content}"),
StepOutcome::ToolExecuted { tool_name, output } => {
println!("[tool: {tool_name}] {output}")
}
}
Ok(())
}
For the CLI, this mostly proves the command wiring. The mock response is a final envelope, so the command prints the final content.
The more interesting tests are in the core crate, where we can script different model envelopes:
File: abcb/crates/abcb-core/src/lib.rs
#[test]
fn run_step_executes_tool_for_tool_call_envelope() {
let mut provider = MockProvider::new([
r#"{"kind":"tool_call","tool_name":"stub_echo","arguments":{"text":"pong"}}"#,
]);
let registry = registry_with_stub_echo();
let outcome = run_step(&mut provider, ®istry, "hi").expect("step should succeed");
assert_eq!(
outcome,
StepOutcome::ToolExecuted {
tool_name: "stub_echo".into(),
output: "pong".into(),
}
);
}
That test shows the actual agent-framework move: the provider returns a structured tool request, run_step parses it, the registry finds the tool, the tool runs, and the step reports the output.
A full agent run will usually contain values like these:
Message { role: System, content: "Return a ModelOutput JSON object." }
Message { role: User, content: "Echo hello." }
Message { role: Assistant, content: "{\"kind\":\"tool_call\",\"tool_name\":\"echo\",\"arguments\":{\"text\":\"hello\"}}" }
ModelOutput::ToolCall { tool_name: "echo", arguments: {"text": "hello"}, note: None }
StepOutcome::ToolExecuted { tool_name: "echo", output: "hello" }
The current run_step code constructs only the user message, because this chapter is still keeping the step small. The system message in the example shows where the framework's instruction would normally live once we start building the full loop and prompt.
Chapter 7 stops there. In Chapter 8, that tool output can become another conversation message:
Message { role: Tool, content: "hello" }
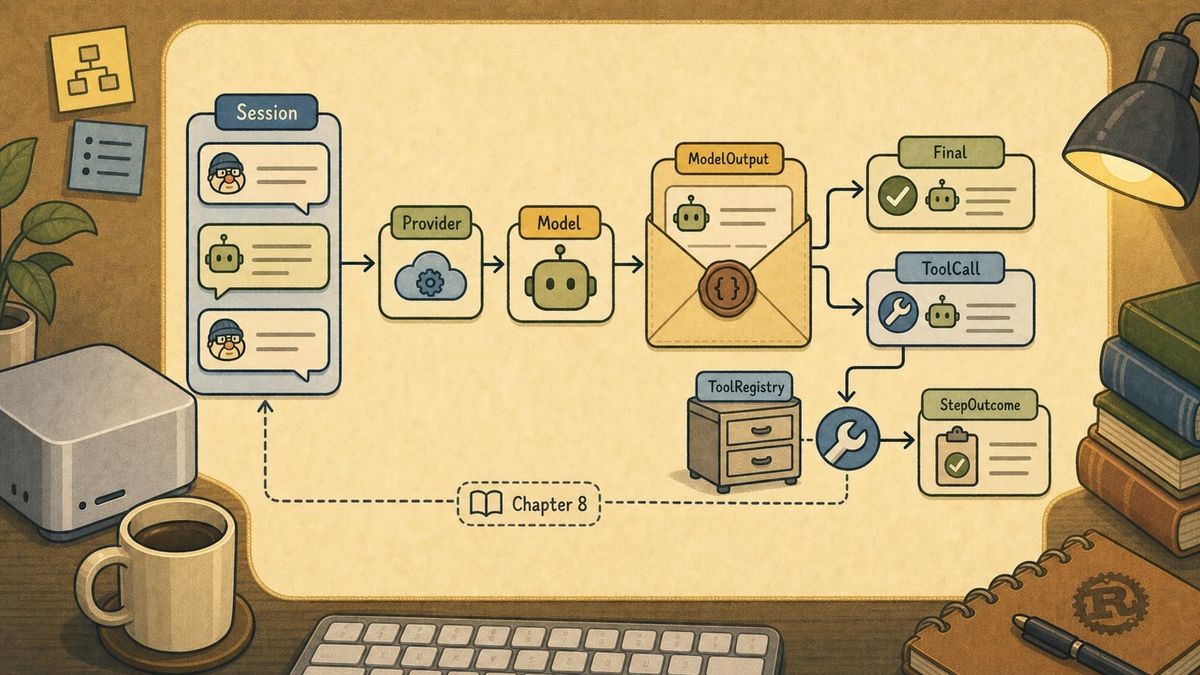
The flow is easier to see as an interaction between the framework, provider, model, registry, and tool. This diagram includes the current Chapter 7 step and the piece that Chapter 8 will add:
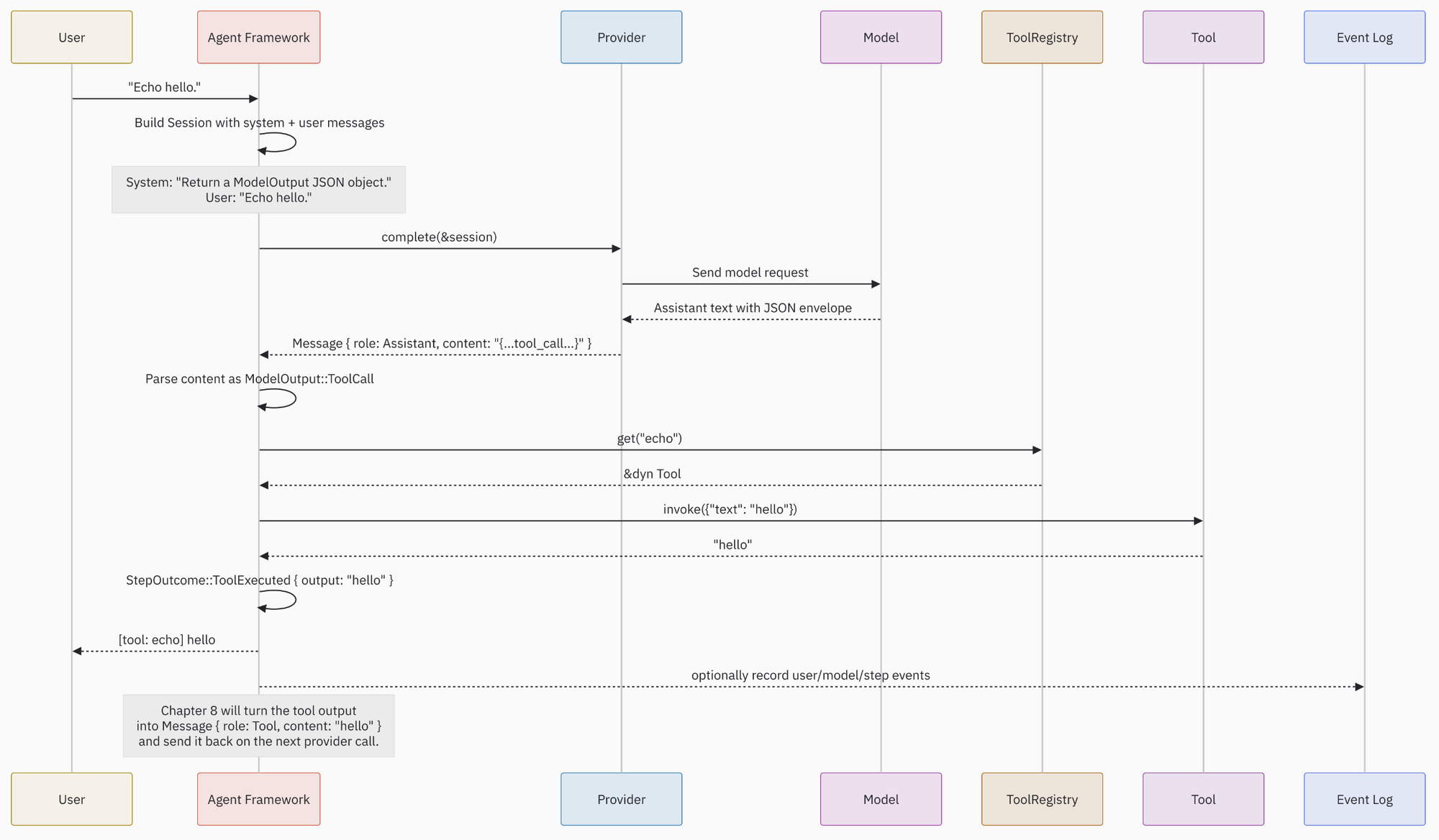
The important thing is that these entries are not all the same kind of object. User, system, assistant, and tool messages are conversation data. ModelOutput is the parsed decision inside the assistant message. StepOutcome is what this one function reports to its caller. Events are the audit records we may write after the framework has done something.
7.10 What We Chose
This chapter makes a few choices that will affect the rest of the framework.
First, the model output is structured JSON, not free text with hidden conventions. That gives the framework something it can parse and match on. Later, we may use a model API's native tool-calling feature, but the internal idea is the same: the model has to speak a shape the framework understands.
Second, tool arguments stay as serde_json::Value at the envelope boundary. The core framework does not know every tool schema. Each tool owns its own argument validation.
Third, errors remain layered. Provider errors, parse errors, missing tools, and tool errors are different. LoopError composes them without erasing where they came from.
Fourth, run_step stops after one decision. If the model returns a final answer, it returns StepOutcome::Final. If the model calls a tool, it executes the tool and returns StepOutcome::ToolExecuted. It does not yet send the tool result back to the model.
That last limitation is not accidental. It is the exact reason we need a loop. A useful tool-using agent usually has to repeat:
- Ask the model.
- Parse the envelope.
- Run a tool if requested.
- Add the tool result to the conversation.
- Ask the model again.
Chapter 7 gives us one clean step. Chapter 8 will make that step repeat.



