Building a Local-First Agent Framework in Rust (Part 11): Going Async and Over HTTP


See Part 0 for the latest table of contents and sample code. New chapters will be added over time.
Chapter 11: Going Async and Over HTTP
Until now, abcb has been living in a controlled room. The provider was a mock. It returned scripted strings from memory. That was not a shortcut in a bad sense. It let us build the conversation type, event log, tool registry, loop, recovery policy, and configuration shape before introducing network behavior.
But an agent framework cannot stay there forever. At some point, the loop must ask a real model for the next message. In the local-first version of this project, that model is not a commercial API by default. It is a model server running on the local machine, exposed through an OpenAI-compatible HTTP endpoint.
This chapter is the first time abcb crosses that boundary.
This post is also available on Medium. If you’re a paid Medium member and happen to read it there, it helps fund my next cup of coffee. Much appreciated ☕️😄
The important word is not "OpenAI" as a company name. The important phrase is OpenAI-compatible as a wire protocol. Many local runtimes can expose a /v1/chat/completions endpoint: MLX, llama.cpp server, Ollama's OpenAI-compatible shim, vLLM, LM Studio, and others. If they accept the same basic request shape and return the same basic response shape, abcb can treat them as the same kind of provider.
OpenAI-compatible does not mean identical
In the OpenAI chat-completions API, the client sends a JSON request with a model name and a list of chat messages. Each message has a role, such asuserorassistant, and some text content. The server returns a JSON response with achoicesarray. Each choice is one possible completion, and the assistant text for the first choice is stored atchoices[0].message.content.
Local runtimes that call themselves OpenAI-compatible usually imitate that request and response shape. They may still disagree on optional fields, model identifiers, error bodies, streaming behavior, tool-calling support, and chat-template details. So in this chapter, "compatible" means practical compatibility with the small part of the API thatabcbneeds, not a guarantee that every OpenAI API feature exists.
That gives us the framework change:
File: abcb/Cargo.toml
[workspace]
members = ["crates/abcb-cli", "crates/abcb-core", "crates/abcb-models", "crates/abcb-tools"]
resolver = "3"
The new crate is abcb-models. It is where model backends live. abcb-core still owns the provider trait, messages, sessions, loop, and tools. abcb-cli wires everything together. But HTTP client code does not belong in core. The core crate should not need to know whether a provider talks to MLX, a local llama.cpp server, or a remote endpoint. It should only know that a provider can complete a session.
The sample code for this chapter is in chapter11/abcb/.
11.1 The Model Crate
The workspace adds two dependencies that matter for this chapter:
File: abcb/Cargo.toml
[workspace.dependencies]
reqwest = { version = "0.12.28", default-features = false, features = ["json", "rustls-tls"] }
tokio = { version = "1.52.3", features = ["macros", "rt"] }
reqwest is the HTTP client. The json feature lets us send JSON request bodies and receive response bodies conveniently. The rustls-tls feature uses Rustls for TLS instead of depending on a platform TLS backend through native-tls. That matters because native TLS can pull in system-specific requirements, such as OpenSSL on some Unix-like environments, or behave slightly differently across platforms. Rustls gives us a Rust-native TLS stack with more predictable builds. For a small local-first tool, reducing that kind of installation friction is useful, even if the first local endpoint is usually plain HTTP.
tokio is the async runtime. HTTP I/O is not immediate. A request may wait for the server, the model, or the network stack. Rust represents that waiting with futures, async functions, and .await, but those futures still need a runtime to drive them. In this chapter, Tokio provides that runtime.
11.1.1 Futures
A future is a value that represents work that may finish later. The idea is not unique to Rust. Many languages have a way to represent "I have started something, and I will get the result in the future." In Rust, that idea is represented by the Future trait.
An async block or async fn produces a future. Calling an async function does not immediately run the whole function body to completion. It creates a future. That future is like a small state machine: it knows where the async function currently is, what it is waiting for, and what should happen next.
Something has to drive that state machine forward. That "something" is the runtime. The runtime repeatedly asks a future whether it can make progress. In Rust terms, it polls the future. A poll can end in one of two broad answers: the future is ready with a value, or the future is still pending.
The important place in normal async code is .await. When a future reaches .await, it is waiting on another future. If that inner future is already ready, execution continues. If it is not ready, the outer future becomes pending and gives control back to the runtime. That point is often called a yield point. After a yield point, the runtime is free to poll some other future.
This model is cooperative. The runtime does not stop a future at an arbitrary line of code and move on to another one. The future must reach a place where it can yield, usually an .await. That is why blocking calls are dangerous inside async tasks. If a future calls std::thread::sleep, that call does not return "pending" to the runtime. It simply occupies the operating-system thread until the sleep is over. While that thread is inside std::thread::sleep, the runtime cannot use the same thread to poll another future.
This is separate from the question of how many threads the runtime uses. A future itself does not assume a single-threaded model. Tokio can run futures on a current-thread runtime or a multi-threaded runtime. Later in this chapter, abcb chooses Tokio's current-thread runtime because the CLI loop is sequential. That is our runtime choice, not a property of every future.
Current-thread runtime
A current-thread runtime runs async tasks on one operating-system thread. It can still switch between many futures, but only when those futures yield. A multi-threaded runtime has multiple worker threads and can poll different tasks on different threads.abcbuses the current-thread flavor in this chapter because the CLI performs one provider call at a time.
When we say "use an async version of the operation," it does not mean simply wrapping blocking code in an async block. We mean using an API that is designed to cooperate with the runtime. An async HTTP client, for example, can start a request, return "pending" while the socket is waiting, arrange to be woken when data is ready, and let the runtime poll other futures in the meantime. If work is truly blocking and has no async API, the usual answer is to run it on a dedicated blocking thread pool instead of doing it directly in the async task.
For this chapter, the important future is the HTTP request. Sending a request to a model server may take time. The provider should not pretend that waiting is instant, so its method becomes async.
11.1.2 Runtimes
Rust the language does not prescribe one async runtime. It gives us the Future trait, the async keyword, and the .await operator. The runtime implementation is mostly left to libraries.
That separation can be surprising at first. In some languages, async syntax and the event loop feel like one bundled system. In Rust, the syntax is part of the language, but the executor, timers, networking integration, task scheduling, and other runtime services come from crates. The language describes what a future is. The runtime decides how futures are scheduled and how they connect to I/O.
The common runtime choices include Tokio, async-std, and smol. Tokio is the full-featured and most widely used option for network services and application code. async-std presents an API style modeled after Rust's standard library, but async. smol is a smaller runtime with a lightweight design. For most Rust projects that need HTTP clients, servers, or broad ecosystem support, Tokio is the default recommendation.
abcb uses Tokio here because reqwest works naturally with it and because much of the Rust async ecosystem meets there first. We only enable the features this chapter needs: macros for attributes like #[tokio::main] and #[tokio::test], and rt for the runtime itself. We do not enable Tokio's larger feature set yet because this chapter only needs enough runtime support to run the CLI and async tests.
The new crate depends on core, not the other way around:
File: abcb/crates/abcb-models/Cargo.toml
[dependencies]
abcb-core = { path = "../abcb-core" }
reqwest = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
This direction is the architectural point. The provider implementation can use reqwest, serde, and the OpenAI-compatible wire shape. The core crate only exposes the trait and the framework types: Provider, ProviderError, Message, Role, and Session. That keeps abcb-core usable by any provider crate, including one that does not use HTTP at all.
11.2 The Provider Trait Becomes Async
The first visible Rust change is in the provider trait:
File: abcb/crates/abcb-core/src/lib.rs
#[allow(async_fn_in_trait)]
pub trait Provider {
async fn complete(&mut self, session: &Session) -> Result<Message, ProviderError>;
}
Previously, complete returned a Result<Message, ProviderError> directly. That worked for a mock provider because the answer was already in memory. A real provider must send an HTTP request and wait for a response. The function still returns a message or an error, but now the caller must await the future that represents the in-progress work.
The signature is still easy to read:
async fn complete(&mut self, session: &Session) -> Result<Message, ProviderError>;
The provider is borrowed mutably because completing a turn may change provider state. The session is borrowed immutably because the provider only needs to read the current conversation. The result is still an assistant Message or a ProviderError. The new part is async, which says: this function may pause while waiting for I/O.
The attribute above the trait deserves a little explanation:
#[allow(async_fn_in_trait)]
Rust supports async fn in traits, but a public trait with async fn triggers a warning. The warning is not saying this code is broken. It is saying that the public trait is defining an API contract for the future returned by complete, and that contract is hard to tighten later.
Conceptually, this:
pub trait Provider {
async fn complete(&mut self, session: &Session) -> Result<Message, ProviderError>;
}
is close to saying:
use std::future::Future;
pub trait Provider {
fn complete<'a>(
&'a mut self,
session: &'a Session,
) -> impl Future<Output = Result<Message, ProviderError>> + 'a;
}
The returned future is some concrete future type chosen by each implementor, but the trait does not say that this future is Send.
Rust: SendSendis a marker trait for values that can be moved safely from one thread to another. Most ordinary owned values, such asString, areSend. Some values are not, usually because they rely on thread-local state or non-thread-safe shared ownership. You usually do not implementSendby hand. The compiler derives it automatically when all the parts of a type are safe to send.
Why would Send matter here? A multi-threaded async runtime may move a task from one worker thread to another while it is waiting. For that to be safe, the future inside the task must be safe to move between threads. So if a framework wants to support providers running freely on a multi-threaded runtime, it may want the provider's returned future to be Send.
If we wanted Provider to require that every provider completion future is safe to move between threads, the conceptual signature would need to include Send:
use std::future::Future;
pub trait Provider {
fn complete<'a>(
&'a mut self,
session: &'a Session,
) -> impl Future<Output = Result<Message, ProviderError>> + Send + 'a;
}
Adding that Send requirement later would be a breaking change. Existing provider implementations might return futures that are valid on one thread but not movable to another. That is the flexibility issue behind the warning.
There is no compact stable syntax like this:
/// This is invalid syntax!
pub trait Provider {
async fn complete(&mut self, session: &Session) -> Result<Message, ProviderError> + Send;
}
That is not valid Rust. If the trait itself needs to require a Send future, the usual choices are to write the return future explicitly, use an associated future type, or use a boxing helper pattern. For this book's current code, the explicit return-future shape above is the easiest way to see what the warning is about. We are not choosing it yet because abcb does not need that requirement yet.
abcb is not doing that yet. The loop is sequential. The CLI uses a current-thread runtime. One provider is called at a time, and we await it before moving on. So the simpler native async fn trait is a good fit for this teaching checkpoint. If the framework later becomes a daemon that runs many tasks concurrently, this decision would be worth revisiting.
Rust: async and await
Anasync fndoes not run to completion immediately. It returns a future. Calling.awaitgives the runtime permission to drive that future until it produces a value. While the future is waiting for I/O, the runtime can do other work. In this chapter, we mostly use async for honest waiting, not for parallelism.
Concurrency is not parallelism
Concurrency means the program can make progress on more than one task over the same period of time. Parallelism means work is literally running at the same instant, usually on multiple CPU cores. A single-threaded runtime can still be concurrent if tasks yield while waiting. This chapter uses async for concurrency around I/O waiting, not for CPU parallelism.
The mock provider also becomes async:
File: abcb/crates/abcb-core/src/lib.rs
impl Provider for MockProvider {
async fn complete(&mut self, _session: &Session) -> Result<Message, ProviderError> {
let content = self
.scripted
.pop_front()
.ok_or(ProviderError::NoMoreResponses)?;
Ok(Message::new(Role::Assistant, content))
}
}
This function does not actually wait for I/O, but it must implement the same trait as the real provider. That is a useful constraint. The loop should not care whether a provider is scripted or real. Both providers have the same contract.
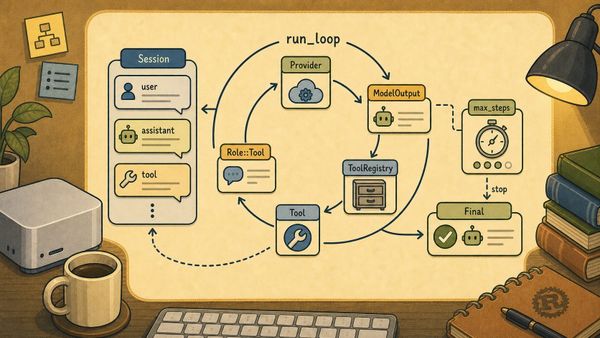
11.3 Async Spreads Through the Loop
Once the trait becomes async, every caller that touches the provider must also become async.
File: abcb/crates/abcb-core/src/lib.rs
pub async fn one_turn(
provider: &mut impl Provider,
user_message: impl Into<String>,
) -> Result<Message, ProviderError> {
let mut session = Session::new("one-turn");
session.push_message(Message::new(Role::User, user_message));
provider.complete(&session).await
}
The only operational change inside one_turn is the .await:
provider.complete(&session).await
This is one of the nice things about introducing async after the loop already exists. The structure of the code does not change very much. The function still creates a session, pushes the user message, calls the provider, and returns the reply. The waiting point is explicit.
The same thing happens in the agent loop:
File: abcb/crates/abcb-core/src/lib.rs
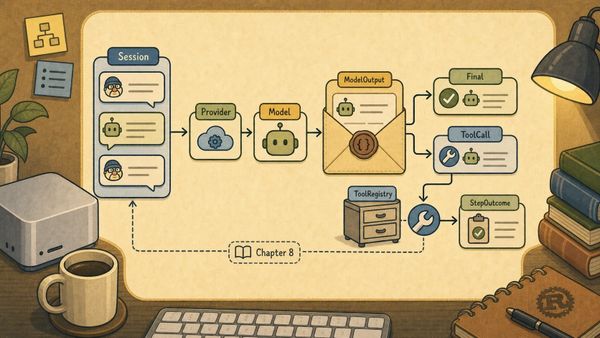
pub async fn run_step(
provider: &mut impl Provider,
registry: &ToolRegistry,
session: &mut Session,
) -> Result<StepOutcome, LoopError> {
let reply = provider.complete(session).await?;
session.push_message(Message::new(Role::Assistant, reply.content.clone()));
let output = ModelOutput::parse(&reply.content)?;
match output {
ModelOutput::Final { content } => Ok(StepOutcome::Final(content)),
ModelOutput::ToolCall {
tool_name,
arguments,
..
} => {
let tool = registry
.get(&tool_name)
.ok_or_else(|| LoopError::UnknownTool(tool_name.clone()))?;
let output = tool.invoke(&arguments)?;
session.push_message(Message::new(Role::Tool, output.clone()));
Ok(StepOutcome::ToolExecuted { tool_name, output })
}
}
}
The provider call is async. The tool call is still synchronous:
let output = tool.invoke(&arguments)?;
That distinction is intentional for now. This chapter is about model I/O over HTTP. Tools remain local functions. Later, a tool might call the filesystem, a subprocess, or another service, and then we would need to decide whether the tool trait should also become async. We do not pay that complexity before the code needs it.
The outer loop awaits each step:
File: abcb/crates/abcb-core/src/lib.rs
pub async fn run_loop(
provider: &mut impl Provider,
registry: &ToolRegistry,
user_message: impl Into<String>,
max_steps: usize,
) -> Result<String, LoopError> {
let mut session = Session::new("run-loop");
session.push_message(Message::new(Role::User, user_message));
for _ in 0..max_steps {
match run_step(provider, registry, &mut session).await {
Ok(StepOutcome::Final(answer)) => return Ok(answer),
Ok(StepOutcome::ToolExecuted { .. }) => {}
Err(e) => match e.recovery_feedback() {
Some(feedback) => session.push_message(Message::new(Role::Tool, feedback)),
None => return Err(e),
},
}
}
Err(LoopError::MaxStepsExceeded { max_steps })
}
This is still a sequential agent loop. It calls the provider, waits for the response, parses the response, maybe invokes one tool, feeds the result back, and repeats. Async does not automatically mean parallel. In this chapter, async mainly means the loop can honestly represent an operation that waits outside the process.
11.4 Error Types at the Provider Boundary
When the provider was only a mock, its error type could be very concrete:
NoMoreResponses
With HTTP in the picture, provider errors become broader. A provider might fail because the URL is wrong, the server is not running, TLS fails, the response is not JSON, the response has no choices, or the server returns a non-success status.
We could pull all of those error types into abcb-core, but that would be the wrong direction. Core should not know about reqwest. It should not need to know the exact JSON parser error used by a specific provider crate. It needs a way to say: the provider backend failed.
File: abcb/crates/abcb-core/src/lib.rs
#[derive(Debug)]
pub enum ProviderError {
NoMoreResponses,
Backend(Box<dyn std::error::Error + Send + Sync>),
}
Backend is intentionally abstract. It holds a boxed error trait object:
Box<dyn std::error::Error + Send + Sync>
Read that from the inside out. dyn std::error::Error means "some concrete type that implements the standard error trait, but we do not name that type here." Box<...> puts that unknown-sized value behind a pointer so the enum can store it. Send + Sync says the boxed error is safe to move or reference across thread boundaries. Even though this chapter uses a current-thread runtime, those bounds are common for async error values and keep the type from becoming awkward later.
This is the trade. abcb-core stays HTTP-free, but ProviderError can no longer derive Eq or PartialEq. A boxed trait object does not have a general equality operation. The practical difference is the question the test asks.
assert_eq! asks: "Is this entire value equal to that entire value?" That worked when every ProviderError variant was simple enough to compare:
assert_eq!(err, ProviderError::NoMoreResponses);
But after adding Backend(Box<dyn Error + Send + Sync>), the enum can contain an opaque error value:
ProviderError::Backend(/* some boxed error we do not know how to compare */)
To compare the whole enum, Rust would also need to compare the boxed error inside Backend. That boxed value might contain a reqwest::Error, a serde_json::Error, or some other error type. There is no general rule for comparing all possible error trait objects.
matches! asks a smaller question: "Does this value have this enum variant shape?" It does not compare the hidden value inside _.
So the tests now check the shape of the error instead:
File: abcb/crates/abcb-models/src/lib.rs
assert!(matches!(err, ProviderError::Backend(_)));
That keeps the test focused on the framework decision: this was a backend failure. It does not try to compare the exact boxed error value inside the variant.
The display implementation keeps the top-level message readable:
File: abcb/crates/abcb-core/src/lib.rs
impl fmt::Display for ProviderError {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
match self {
ProviderError::NoMoreResponses => write!(f, "no more scripted responses"),
ProviderError::Backend(e) => write!(f, "provider backend error: {e}"),
}
}
}
The Error implementation keeps the original source error available:
File: abcb/crates/abcb-core/src/lib.rs
impl std::error::Error for ProviderError {
fn source(&self) -> Option<&(dyn std::error::Error + 'static)> {
match self {
ProviderError::NoMoreResponses => None,
ProviderError::Backend(e) => Some(&**e),
}
}
}
The small expression &**e can look strange the first time you see it.
e is a reference to a Box<dyn Error + Send + Sync>. One * dereferences the reference and reaches the Box. The next * dereferences the Box and reaches the error trait object inside it. Then & borrows that inner error again, producing the reference type expected by source():
&(dyn std::error::Error + 'static)
This is not a new ownership transfer. The boxed error stays inside ProviderError. The source() method only returns a borrowed view of it so callers can inspect the error chain.
Rust: trait objects at a boundary
A trait object (ordyn Trait) is a value accessed through a trait instead of through its concrete type. Indyn std::error::Error, thedynkeyword says: this is some type that implementsError, but the exact type is hidden behind the trait interface. Because the concrete size is not known at compile time, we usually put a trait object behind a pointer such asBox,&, orArc.
That is useful at a crate boundary.abcb-modelsmay create areqwest::Error, aserde_json::Error, or a string-based error.abcb-coredoes not need to name those concrete types. It stores them all as "some standard error" and keeps its dependency list small.
11.5 The OpenAI-Compatible Provider
The new provider type lives in abcb-models:
File: abcb/crates/abcb-models/src/lib.rs
use abcb_core::{Message, Provider, ProviderError, Role, Session};
use serde::{Deserialize, Serialize};
#[derive(Debug)]
pub struct OpenAiCompatProvider {
client: reqwest::Client,
base_url: String,
model: String,
}
The struct stores three things. client is the reusable HTTP client. base_url is the OpenAI-compatible base endpoint, such as http://localhost:8083/v1. model is the model identifier that the server expects in the request body. Together, these fields are enough to turn an internal Session into one HTTP request.
Local model setup is outside this chapter
This chapter assumes that an OpenAI-compatible model server is already running somewhere, usually onlocalhost. The provider only needs the server's base URL and model identifier. It does not install MLX, download a model, choose quantization, or start the server process. I covered one concrete local setup path in Running Gemma 4 Locally with MLX, and the same provider shape should also work with other OpenAI-compatible runtimes.
Construction is deliberately boring:
File: abcb/crates/abcb-models/src/lib.rs
impl OpenAiCompatProvider {
pub fn new(base_url: impl Into<String>, model: impl Into<String>) -> Self {
Self {
client: reqwest::Client::new(),
base_url: base_url.into(),
model: model.into(),
}
}
}
The constructor takes impl Into<String> for both fields. That lets callers pass a String or a &str, and the provider owns the final strings. This matches the lifetime of the provider: once it is built, it should not depend on the config struct staying alive.
The name OpenAiCompatProvider is a little long, but it is precise. It is not an MlxProvider, OllamaProvider, or LlamaCppProvider. Those are deployment choices. The provider is organized around the wire contract it speaks.
That matters because local model tooling changes quickly. If the next server exposes the same /v1/chat/completions shape, the provider does not need a new Rust type. The config changes, not the framework shape.
11.6 Building the Request Without Copying the Conversation
The provider builds a request from the current session:
File: abcb/crates/abcb-models/src/lib.rs
impl OpenAiCompatProvider {
fn build_request<'a>(&'a self, session: &'a Session) -> ChatRequest<'a> {
ChatRequest {
model: &self.model,
messages: session
.messages
.iter()
.map(|m| WireMessage {
role: wire_role(&m.role),
content: &m.content,
})
.collect(),
stream: false,
}
}
}
The return type is ChatRequest<'a>, and that lifetime is doing real work. The request does not copy the model string or every message's content string. It borrows them:
File: abcb/crates/abcb-models/src/lib.rs
#[derive(Serialize)]
struct ChatRequest<'a> {
model: &'a str,
messages: Vec<WireMessage<'a>>,
stream: bool,
}
#[derive(Serialize)]
struct WireMessage<'a> {
role: &'a str,
content: &'a str,
}
The request borrows self.model and the text inside session.messages. That is why build_request ties both input references to the same lifetime:
fn build_request<'a>(&'a self, session: &'a Session) -> ChatRequest<'a>
This says: the returned ChatRequest cannot outlive the provider or the session it borrowed from. That is exactly what we want. The request is a temporary serialization view. It exists long enough to become a JSON body.
The HTTP call uses it like this:
File: abcb/crates/abcb-models/src/lib.rs
let request = self.build_request(session);
let response = self
.client
.post(&url)
.json(&request)
.send()
.await
.map_err(|e| ProviderError::Backend(Box::new(e)))?;
The key is that reqwest serializes the JSON body before the request future needs to keep borrowing our session across the network wait. In this code, the borrowed request is used to build the outgoing body, and then we await the send. The session itself remains owned by the caller.
Rust: lifetimes as a borrow contract
A lifetime annotation does not make a value live longer. It describes how long borrowed references are valid. Here,ChatRequest<'a>says the request is only a borrowed view over existing provider and session data. The compiler prevents us from returning that borrowed view to a place where the provider or session might already be gone.
11.7 Roles on the Wire
Internally, abcb has four roles:
File: abcb/crates/abcb-core/src/lib.rs
pub enum Role {
User,
Assistant,
System,
Tool,
}
The OpenAI-compatible chat format has similar roles, but the match is not perfect. In particular, a real "tool" role in OpenAI's schema usually expects fields like tool_call_id. Our framework does not use that native tool-calling API. We built our own JSON envelope and feed tool results back into the conversation as text.
Is it okay to send tool output as user text?
Yes, because we are still sending a valid chat message. We are not sending an OpenAI"tool"message without the extra fields that OpenAI's native tool-calling schema expects. Instead, we choose a simpler contract: tool output becomes plain text in ausermessage. That keeps the request inside the basicuser/assistant/systemchat format supported by many local runtimes.
The tradeoff is semantic, not syntactic. The HTTP server can accept the request, but the model still has to understand from the text that this message contains a tool result. That is why the wording of tool-result messages matters, and why later chapters keep testing how the model reacts to the loop.
So the provider maps roles explicitly:
File: abcb/crates/abcb-models/src/lib.rs
fn wire_role(role: &Role) -> &'static str {
match role {
Role::User => "user",
Role::Assistant => "assistant",
Role::System => "system",
Role::Tool => "user",
}
}
The first three cases are direct. The last one is a deliberate compromise:
Role::Tool => "user",
For local model servers, this is often the practical path. The model needs to see the tool result before it decides the next step. If the server's chat template only understands user, assistant, and system turns, then a tool result can be fed back as a user-side observation.
The test says the same thing in executable form:
File: abcb/crates/abcb-models/src/lib.rs
#[test]
fn wire_role_maps_tool_to_user() {
assert_eq!(wire_role(&Role::User), "user");
assert_eq!(wire_role(&Role::Assistant), "assistant");
assert_eq!(wire_role(&Role::System), "system");
assert_eq!(wire_role(&Role::Tool), "user");
}
This is one of those places where a test is also documentation. It tells a future reader that Tool becoming "user" is not an accident.
11.8 Sending the Request
Now we can look at the real provider implementation:
File: abcb/crates/abcb-models/src/lib.rs
impl Provider for OpenAiCompatProvider {
async fn complete(&mut self, session: &Session) -> Result<Message, ProviderError> {
let url = format!("{}/chat/completions", self.base_url.trim_end_matches('/'));
let request = self.build_request(session);
let response = self
.client
.post(&url)
.json(&request)
.send()
.await
.map_err(|e| ProviderError::Backend(Box::new(e)))?;
let status = response.status();
let body = response
.text()
.await
.map_err(|e| ProviderError::Backend(Box::new(e)))?;
if !status.is_success() {
return Err(ProviderError::Backend(
format!("HTTP {status} from {url}: {body}").into(),
));
}
let content = parse_response(&body)?;
Ok(Message::new(Role::Assistant, content))
}
}
The URL construction trims a trailing slash from the configured base URL:
let url = format!("{}/chat/completions", self.base_url.trim_end_matches('/'));
That makes both of these work:
http://localhost:8083/v1
http://localhost:8083/v1/
Both become a request to:
http://localhost:8083/v1/chat/completions
The request body is JSON:
.json(&request)
The request is sent asynchronously:
.send().await
If reqwest fails, the provider maps the concrete error into the core boundary type:
.map_err(|e| ProviderError::Backend(Box::new(e)))?
That line is a small example of the crate boundary in action. reqwest::Error stays in abcb-models. Outside this crate, callers only see ProviderError::Backend.
After the response arrives, the code saves the status before consuming the response body:
File: abcb/crates/abcb-models/src/lib.rs
let status = response.status();
let body = response
.text()
.await
.map_err(|e| ProviderError::Backend(Box::new(e)))?;
response.text().await consumes the response. Reading the status first lets us include both the HTTP status and the body in an error message:
File: abcb/crates/abcb-models/src/lib.rs
if !status.is_success() {
return Err(ProviderError::Backend(
format!("HTTP {status} from {url}: {body}").into(),
));
}
This is not fancy error modeling. It is practical. When a local model server returns an error, I want the CLI to show me the status and the body. Otherwise the debugging loop becomes much slower.
11.9 Parsing the Response
The provider does not return the whole JSON response. It extracts the first assistant message:
File: abcb/crates/abcb-models/src/lib.rs
fn parse_response(body: &str) -> Result<String, ProviderError> {
let parsed: ChatResponse =
serde_json::from_str(body).map_err(|e| ProviderError::Backend(Box::new(e)))?;
parsed
.choices
.into_iter()
.next()
.map(|choice| choice.message.content)
.ok_or_else(|| ProviderError::Backend("response contained no choices".into()))
}
The response structs are just enough for the fields we need:
File: abcb/crates/abcb-models/src/lib.rs
#[derive(Deserialize)]
struct ChatResponse {
choices: Vec<Choice>,
}
#[derive(Deserialize)]
struct Choice {
message: ResponseMessage,
}
#[derive(Deserialize)]
struct ResponseMessage {
content: String,
}
Serde allows us to deserialize a subset of a larger JSON object. The server may return IDs, usage counts, timestamps, and other fields. These structs only care about choices[0].message.content. That keeps the provider focused on the framework contract: produce the next assistant message.
There are two failure paths here. Malformed JSON becomes a boxed backend error:
serde_json::from_str(body).map_err(|e| ProviderError::Backend(Box::new(e)))?
An otherwise valid response with no choices becomes a string-based backend error:
ProviderError::Backend("response contained no choices".into())
That .into() works because standard library types provide conversions that can turn strings into boxed error values when the target type is Box<dyn Error + Send + Sync>. The call site does not need to write the concrete wrapper type.
The tests exercise the provider's local logic without starting a server:
File: abcb/crates/abcb-models/src/lib.rs
#[test]
fn parse_response_extracts_first_choice_content() {
let body = r#"{"choices":[{"message":{"role":"assistant","content":"hello there"}}]}"#;
let content = parse_response(body).expect("should parse");
assert_eq!(content, "hello there");
}
And the error cases:
File: abcb/crates/abcb-models/src/lib.rs
#[test]
fn parse_response_errors_on_empty_choices() {
let body = r#"{"choices":[]}"#;
let err = parse_response(body).expect_err("no choices should error");
assert!(matches!(err, ProviderError::Backend(_)));
}
#[test]
fn parse_response_errors_on_malformed_json() {
let err = parse_response("not json").expect_err("malformed should error");
assert!(matches!(err, ProviderError::Backend(_)));
}
This chapter does not add a full integration test against a live local model server. That is a separate kind of test, because it depends on an external process and a configured model. Here, the unit tests pin down request construction, role mapping, and response parsing.
11.10 The CLI Enters the Runtime
Async code needs a place to start. In the CLI, that place is main:
File: abcb/crates/abcb-cli/src/main.rs
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn Error>> {
let cli = Cli::parse();
match cli.command {
Command::Doctor => run_doctor()?,
Command::Chat { message, mock, log } => run_chat(message, mock, log).await?,
Command::Replay { path } => run_replay(path)?,
Command::Run { message, mock } => run_run(message, mock).await?,
}
Ok(())
}
#[tokio::main] is an attribute macro. It rewrites the async main function into a normal synchronous entry point that creates a Tokio runtime and runs the future produced by main.
The flavor = "current_thread" setting is part of the design of this checkpoint. abcb is still a sequential CLI. We do not need a multi-threaded executor just to send one HTTP request at a time. A current-thread runtime is enough.
Only commands that touch the provider need .await:
Command::Chat { message, mock, log } => run_chat(message, mock, log).await?,
Command::Run { message, mock } => run_run(message, mock).await?,
The local commands remain synchronous:
Command::Doctor => run_doctor()?,
Command::Replay { path } => run_replay(path)?,
This is another useful boundary. Async does not need to infect every function in the program. It spreads along call paths that actually await async work.
11.11 Config Chooses the Real Provider
Chapter 10 introduced [model] config. In this chapter, that config becomes runtime wiring.
File: abcb/crates/abcb-cli/src/main.rs
fn load_required_config() -> Result<Config, Box<dyn Error>> {
let config = load_config(Path::new("abcb.toml"))?
.ok_or("no abcb.toml found; add a [model] section or pass --mock")?;
Ok(config)
}
Earlier, a missing abcb.toml was not an error. That is still true for doctor, replay, and mock-mode commands. But if the user asks for the real provider path, the CLI needs model settings. So the real path calls load_required_config.
Then the provider is built from [model]:
File: abcb/crates/abcb-cli/src/main.rs
fn build_provider(config: &Config) -> Result<OpenAiCompatProvider, Box<dyn Error>> {
let model = config
.model
.as_ref()
.ok_or("abcb.toml has no [model] section; add one or pass --mock")?;
Ok(OpenAiCompatProvider::new(
model.base_url.as_str(),
model.model.as_str(),
))
}
The config owns its strings. The provider constructor accepts borrowed &str values here:
model.base_url.as_str(),
model.model.as_str(),
Inside OpenAiCompatProvider::new, those borrowed strings become owned String fields. So the provider does not borrow from Config. The config can go out of scope after provider construction.
The real and mock paths stay as two branches. In the mock branch, the CLI creates a MockProvider with a scripted final answer and does not require abcb.toml. In the real branch, the CLI loads config, builds an OpenAiCompatProvider, and uses the configured max_steps.
File: abcb/crates/abcb-cli/src/main.rs
async fn run_run(message: String, mock: bool) -> Result<(), Box<dyn Error>> {
let registry = default_registry(PathBuf::from(NOTES_PATH));
let answer = if mock {
let mut provider = MockProvider::new([format!(
r#"{{"kind":"final","content":"mock run: you said {message}"}}"#
)]);
run_loop(&mut provider, ®istry, &message, DEFAULT_MAX_STEPS).await?
} else {
let config = load_required_config()?;
let mut provider = build_provider(&config)?;
run_loop(&mut provider, ®istry, &message, config.max_steps()).await?
};
println!("{answer}");
Ok(())
}
At first, it may seem nicer to create one provider variable before calling run_loop, then choose which provider value to assign to it. But the two branches produce different concrete provider types: MockProvider in the first branch and OpenAiCompatProvider in the second.
run_loop is generic over impl Provider:
provider: &mut impl Provider
That means each call is compiled for one concrete provider type. It does not mean a single variable can hold either provider type. We could use dynamic dispatch, such as Box<dyn Provider>, but async methods in traits make that path more complicated, and we do not need it here. Two explicit branches are simpler and clearer.
The same branching appears in run_chat:
File: abcb/crates/abcb-cli/src/main.rs
async fn run_chat(message: String, mock: bool, log: Option<PathBuf>) -> Result<(), Box<dyn Error>> {
let reply = if mock {
let mut provider = MockProvider::new([format!("mock: you said {message}")]);
one_turn(&mut provider, &message).await?
} else {
let config = load_required_config()?;
let mut provider = build_provider(&config)?;
one_turn(&mut provider, &message).await?
};
println!("{}", reply.content);
if let Some(path) = log {
let file = OpenOptions::new().append(true).create(true).open(&path)?;
let mut writer = BufWriter::new(file);
write_event(
&mut writer,
&Event::UserMessage {
content: message.clone(),
},
)?;
write_event(
&mut writer,
&Event::ModelResponse {
content: reply.content.clone(),
},
)?;
write_event(
&mut writer,
&Event::FinalAnswer {
content: reply.content,
},
)?;
}
Ok(())
}
The event log does not care whether the reply came from a mock or a real model. That is the reward for keeping the provider contract narrow. Once the CLI has a Message, the rest of the code continues as before.
11.12 Async Tests
Tests that call async functions need an async test runtime too. Tokio provides that with #[tokio::test]:
File: abcb/crates/abcb-core/src/lib.rs
#[tokio::test]
async fn one_turn_returns_assistant_reply_from_provider() {
let mut provider = MockProvider::new(["bot reply"]);
let reply = one_turn(&mut provider, "hi")
.await
.expect("one_turn should produce a reply");
assert_eq!(reply, Message::new(Role::Assistant, "bot reply"));
}
The test body looks like normal async code. It awaits one_turn, then checks the result. The attribute macro handles the runtime setup for the test.
The CLI tests do the same thing for paths that now call async functions:
File: abcb/crates/abcb-cli/src/main.rs
#[tokio::test]
async fn run_chat_without_mock_and_without_config_errors() {
let err = run_chat("hi".into(), false, None)
.await
.expect_err("should require config or --mock");
assert!(err.to_string().contains("--mock"));
}
This test is small, but it locks in an important user-facing rule. If the user does not pass --mock, the CLI assumes the real provider path. The real provider path requires config. Without abcb.toml, the error should tell the user either to add [model] or pass --mock.
The provider crate still uses synchronous unit tests for pure functions such as role mapping and response parsing. Not every test becomes async just because the crate has async code. Only tests that await async functions need the async test attribute.
11.13 What Changed
The framework crossed a real boundary in this chapter. The provider contract became async. The loop learned to await model calls. A new abcb-models crate took ownership of OpenAI-compatible HTTP details. The CLI can now choose between the mock provider and a real provider configured through abcb.toml.
The Rust concepts arrived because the code needed them:
async fnand.awaitmodel waiting for HTTP I/O.#[tokio::main]and#[tokio::test]provide runtime entry points.reqwestsends JSON requests and reads response bodies.- Borrowed request structs use lifetimes to serialize model/session data without copying every string.
- Boxed error trait objects keep concrete backend failures out of
abcb-core.
This chapter still leaves several things open. There is no streaming yet. The provider uses stream: false and waits for a whole response body. There is no native OpenAI tool-calling support. Tool results are folded back into the conversation as user-side messages. There is also no live server integration test in the sample code. The unit tests cover the request and response logic, but the real local model path still depends on your local runtime being available and configured.
That is enough for this checkpoint. abcb can now speak to a real model server without letting HTTP take over the core framework. The next question is not "can we send a request?" The next question is whether the local model answers in the shape our loop needs.
To be continued